Species distribution modeling
| Author(s) |
|
| Reviewers |
|
OverviewQuestions:
Objectives:
How to build & evaluate a niche model, visualize and project it?
Requirements:
Find and download occurrences data from GBIF
Find and download environmental data
Process both occurrences and environmental data
Partition occurrence data
Model a theoretical ecological niche and predict species distribution in a future climate scenario by using SDM
Time estimation: 1 hourSupporting Materials:Published: Jul 4, 2019Last modification: May 7, 2026License: Tutorial Content is licensed under Creative Commons Attribution 4.0 International License. The GTN Framework is licensed under MITpurl PURL: https://gxy.io/GTN:T00135rating Rating: 5.0 (0 recent ratings, 3 all time)version Revision: 19
Species Distribution Modeling (SDM) can help understand a species distribution in relation to its environment. It can also attempt to quantify the impact of climate change on the species’ habitat, direct conservation efforts and predict invasive species distributions. This is acheived by associating species occurrence (observations) data with a set of environmental data (such as temperature and precipitation).
The goal of this tutorial is to model a theoretical ecological niche and predict species distribution in a future climate scenario by using an SDM with the Wallace interactive environment on Galaxy. We’ll use the data occurrences of Chrysemys picta (Painted turtle) in the US, North America region.
AgendaIn this tutorial, we will deal with:
Step 1: Import data from public databank
In this study the datasets are all imported from the GBIF databanks. It is also possible to import from BISON, iNaturalist and others.
Hands On: Import the data
Create a new history for this tutorial and give it a proper name
To create a new history simply click the new-history icon at the top of the history panel:
- Click on galaxy-pencil (Edit) next to the history name (which by default is “Unnamed history”)
- Type the new name
- Click on Save
- To cancel renaming, click the galaxy-undo “Cancel” button
If you do not have the galaxy-pencil (Edit) next to the history name (which can be the case if you are using an older version of Galaxy) do the following:
- Click on Unnamed history (or the current name of the history) (Click to rename history) at the top of your history panel
- Type the new name
- Press Enter
- Get species occurrences data tool with the following parameters
- “Scientific name”:
Chrysemys picta- “Data source”:
gbif- “Number of records to return”:
10000- Inspect the generated file with the Scratchbook

We now have a tabular file with 10,001 lines and many columns.
Question
- What do the rows in the files represent?
- What are the columns 1, 2, 3 and 54 of the generated file?
- Each row represents a Chrysemys picta observation, its location, and other metadata
- Column 1 is the name, column 2 the longitude of the observation of Chrysemys picta, column 3 the latitude and column 54 the country code of the location
We will extract the 4 columns mentioned above and keep only the occurrence records from the US.
Hands On: Import the data
- Cut columns tool with the following parameters
- “Cut columns”:
c1,c2,c3,c54- “Delimited by”:
Tab- param-file “From”: output of Get species occurrences data
- Inspect the generated file and check the 4 columns
- Filter data tool with the following parameters
- param-file “Filter”: output of Cut columns
- “With following condition”:
c4=='US'- “Number of header lines to skip”:
1Inspect the generated files
QuestionHow many occurrences were kept?
63.06% of the occurrences (6,306) are conserved
- Tabular to CSV tool
- Click on the Edit Attributes galaxy-pencil option for the output of Filter.
- On the central panel click on the galaxy-gear Convert tab.
- Check the Target data is csv.
- Click on Create Dataset
- Due to an issue related to the GBIF format conversion, each
"sign is triplicated on the resulting file. You need to replace"""for", using for example the Replace tool parts of text tool.
Step 2: Development and evaluation of the SDM using Wallace
Wallace is an R Shiny app integrated into Galaxy. It provides an interactive environment for the rapid and effective development and evaluation of an SDM, it integrates data download, cleaning, partitioning, modeling, visualisation and prediction.
Transmit occurrence data from Galaxy to Wallace
Here, you can either upload your Galaxy data or you can download data directly in Wallace. Let’s use the data from your Galaxy history:
Hands On: Launch Wallace
- Verify your current history has the filtered occurences data.
- Open Wallace in Galaxy or click here to open the tool and click on execute
- Go to User > Active InteractiveTools, then click on the active InteractiveTool named
Wallace visualisation.- In Wallace
- Due to an issue related to the last Wallace Docker update, a manual fix is required. First go to the 5 Partition Occs, select “Spatial Partition” then for “Options available” select
Checkerboard 2 (k=4)then click on the Partition button. This will allow the “Aggregation Factor” option to be displayed. Sorry for the inconvenience.- Go to 1 Occ Data
- In Obtain Occurrence Data
- “Modules Available”:
Galaxy History User- “From Galaxy History User csv file select”: output of Tabular to CSV (or the Replace output if you used that tool).
- Click on Load Occurrences
The data will load on the main panel of Wallace. It can now be inspected using the map, the table, etc.
You now have your occurrence records on Wallace!
Process occurrence data
For the modeling, we need to choose the occurrences we want to use. There is 4 ways to do this in Wallace in the 2 Process Occ panel:
- Selecting occurrences on the map by delimiting an interesting geographic area
- Removing occurrences by ID
-
Delimiting a spatial thin
This allows selecting occurrences by setting a minimum distance (in km) between the different occurrences. For example, by typing 30km, we will get all the occurrences on the map which are at a minimum of 30km from each other.
- Considering all the occurrences
We want to work on the data from the US, we will select the occurrences with the 1st option
Hands On: Select interesting occurrences
- Go to 2 Process Occ
- In Process Occurrence Data
- “Modules Available”: ` Select Occurrences On Map`
- In the middle panel,
- Click on the polygon icon on the map
- Draw a polygon to delimit the area
- On the left panel, click on Select Occurrences
Obtain Environmental Data
Now, we would like to obtain biologically relevant environmental data for our model. The Bioclimatic variables consist of such original and derived variables. We will associate them with the occurrence data, using the WorldClim Bioclims module.
This module provides a raster with environmental variables from online sources. The raster is composed of environmental information. Each layer of the raster contains a climatic variable: starting from BIO1 = Annual mean temperature, to BIO19 = Precipitation of Coldest Quarter.
Hands On: Obtain Environmental Data
- Go to 3 Env Data
- In Obtain Environmental Data
“Modules Available”:
WorldClim BioclimsComment: Using your own rasterIf you prefer to load your own raster:
- Import it into Galaxy in the GeoTIFF format
- In Obtain Environmental Data
- “Modules Available”:
Galaxy History User- “Select from your Galaxy History User csv file”: imported GeoTIFF file Note that if you input your own raster, you don’t have the option for time prediction later on.
“Select WorldClim bioclimatic variable resolution”:
10 arcminThis is the lowest resolution.
- Click on the Load Env Data
Process environmental Data
Wallace will now associate environmental data and occurrences data to train a model.
-
It first creates a buffer zone around the occurrences
We can choose the size of the buffer zone to control the area we will work with and on which a map of suitability will be made.
Several background extents can be used:
- Bounding box defines an area centered on the occurrences
- Minimum convex polygon creates a convex area around the occurrences placement
- Point buffers will use occurrence localities to build a buffer zone around each occurrence
-
It samples Background Points
Hands On: Obtain Environmental Data
- Go to 4 Process Envs
- In Process Environmental Data
- “Modules Available”:
Select Study Region- In Step 1: Choose Background Extent
- “Background Extents”:
Minimum convex polygon- “Study region buffer distance (degree)”:
1- Click on Select
- In Step 2: Sample Background Points
- “No. of background points”:
100000- Click on Sample
Partition Occurrence Data
By partitioning data, a dataset is divided into subsets (i.e. bins). A model is built on each of the subsets but one, it is used to test the model (assuming that all the groups are independent).
There is 2 possible ways to partition data:
- Non-spatial Partition: a partition used when there is no bias due to space, time or sampling method
- Jacknife (k=n): each occurrence in the dataset is considered as equal to a bin. This is usually used when you have a small dataset with no known bias
- Random k-fold: partition the data randomly in a number of bins set by the user with the option
Number of Folds
- Spatial Partition: a partition used when there could be bias due to time, space or sampling method
- Block (k=4): the area is divided in four and the different occurrences are put equally into four bins
- Checkerboard 1 (k=2): two bins are used according to the position of the occurrences on the grid
-
Checkerboard 2 (k=4): four bins are used according to the position of the occurrences on the grid. This requires an aggregation factor, which is the size of a second grid placed on the first one. For example, with a factor 4, the grid’s size will be 4x4
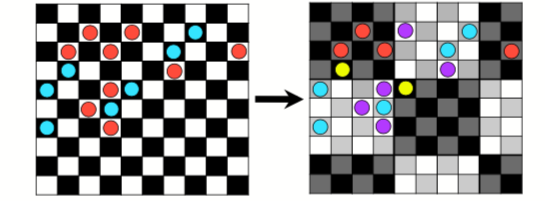 Open image in new tab
Open image in new tabFigure 1: Example of checkerboard (k=4) with a factor 4. Source: doi:10.0.4.87/2041-210X.12261
For both of these techniques the number of occurrences in each bin may vary.
Hands On: Partition Occurrence Data
- Go to 5 Partition Occs
- In Partition Occurrence Data
- “Modules Available”:
Spatial Partition- “Options Available:”:
Checkerboard 2 (k=4)- “Aggregation Factor”:
6- Click on Partition
Build and Evaluate Niche Model
Wallace can build different models using either:
- The presence-only approach BIOCLIM (Module BIOCLIM) (Booth 2018)
- The presence-background (presence-pseudo absence) algorithm Maxent (Module Maxent)
To evaluate these models, Wallace computes the performance on a hold-out dataset (data not used for training) and provides evaluation metrics such as the AUC (Area Under the Curve) mean. As a rule of thumb, an AUC of 0.75 and above is considered good, and closer to 1 is better.
Hands On: Build and evaluate the niche model
- Go to 6 Model
- In Build and Evaluate Niche Model
- “Modules Available”:
BIOCLIM- Click on Run
Visualize Model Results
We would now like to visualize the model of the theoretical niche. First we will make a chart to simulate an ecological niche:
- X-axis: temperature
- Y-axis: the annual precipitation
Hands On: Visualize Model Results
- Go to 7 Visualize
- In Visualize Model Results
- “Modules Available”:
BIOCLIM Envelope Plots- “Axis 1”:
1- “Axis 1”:
12- “Set threshold”:
0.75
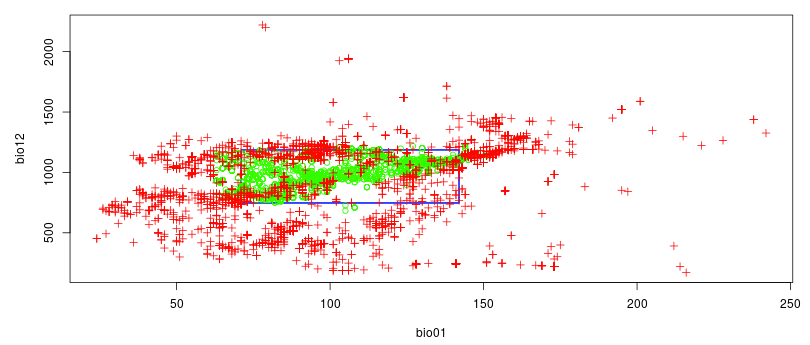
The optimum environmental parameters for this species (represented in green) are between 5°C and 15°C (on the graph, values are x10) with an annual precipitation between approximately 700mm and 1250mm.
To visualize the suitability on the map, we can use the map prediction module.
Hands On: Visualize Model Results
- In Visualize Model Results
- “Modules Available”:
Map Prediction“Set threshold”:
No thresholdIt will display a gradient of predicted presence or use. If you prefer a map with the predicted presence and predicted absence, select
minimum training presence.- Click on Plot
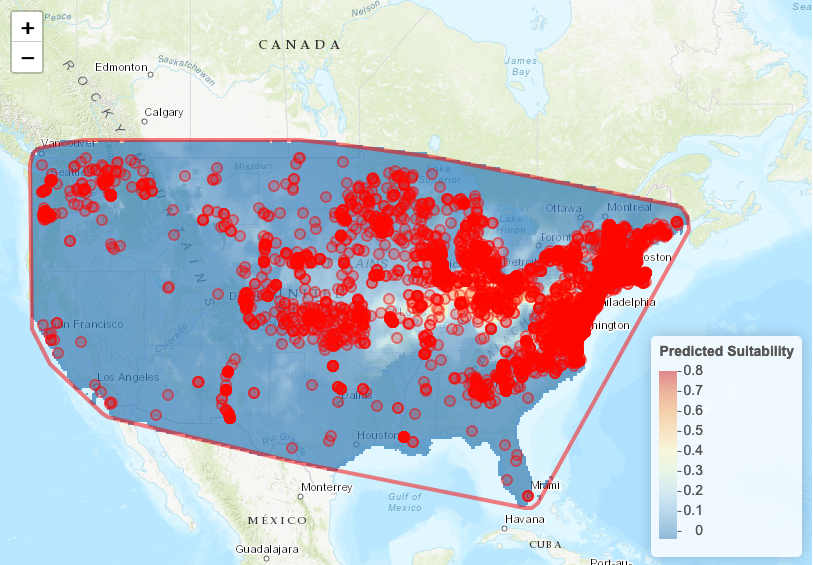
Project Model
Wallace can use the trained model to predict possible species distributions in a different areas, outside of the sampled one. Here, we will try it for Canada.
Hands On: Visualize Model Results
- Go to 8 Project
- In Project Model
- “Modules Available”:
Project to New Extent- In the middle panel,
- Click on the polygon icon on the map
- Draw a polygon around a part of Canada
- In Project Model
- “Set threshold”:
Minimum Training Presence- Click on Project
We can predict not only for a different area, but also for a different time and climate. We use the Global Circulation Models (GCM) to predict atmospheric fluctuation and then evaluate climate change. Each model is different and uses several parameters such as ocean atmosphere. The prediction also uses RCP scenarios, Representative Concentration Pathways take average enegy requirements across the planet (2.6, 4.5, 6.0 and 8.5 watts per meter squared) to model the concentration of greenhouse gases emitted in the near future and their effect on climate. These scenarios may produce varying predicted presence models.
We would like to predict the presence of Chrysemys Picta in Canada in 2050, given the model CCSM4, a US model based on earth circulation, and an RCP value of 2.6
Hands On: Visualize Model Results with a 2.6 RCP
- In Project Model
- “Modules Available”:
Project to New Time- “Select time period”:
2050- “Select global circulation model”:
CCSM4- “Select RCP”:
2.6- “Select threshold”:
Minimum Training Presence- Click on Project
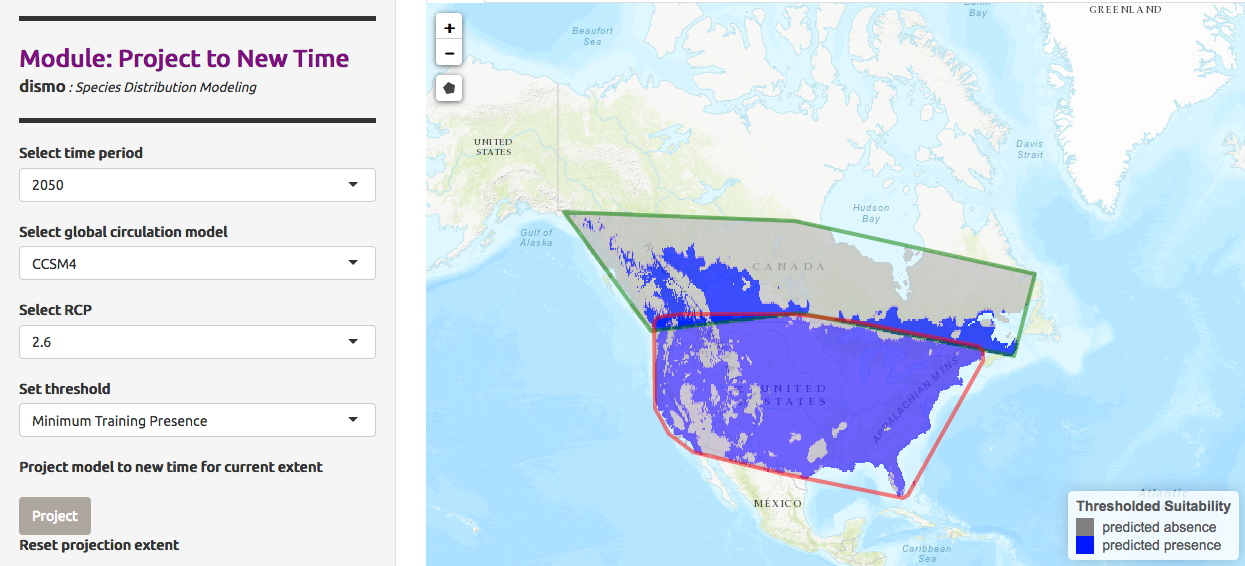
Let’s compare the prediction for the RCP value of 8.5. RCP 8.5 describes a pathway for the current carbon emission without additional constraints, it projects a 4.3˚C temperature increase by 2100.
Hands On: Visualize Model Results with a 8.5 RCP
- In Project Model
- “Modules Available”:
Project to New Time- “Select time period”:
2050- “Select global circulation model”:
CCSM4- “Select RCP”:
8.5- “Select threshold”:
Minimum Training Presence- Click on Project
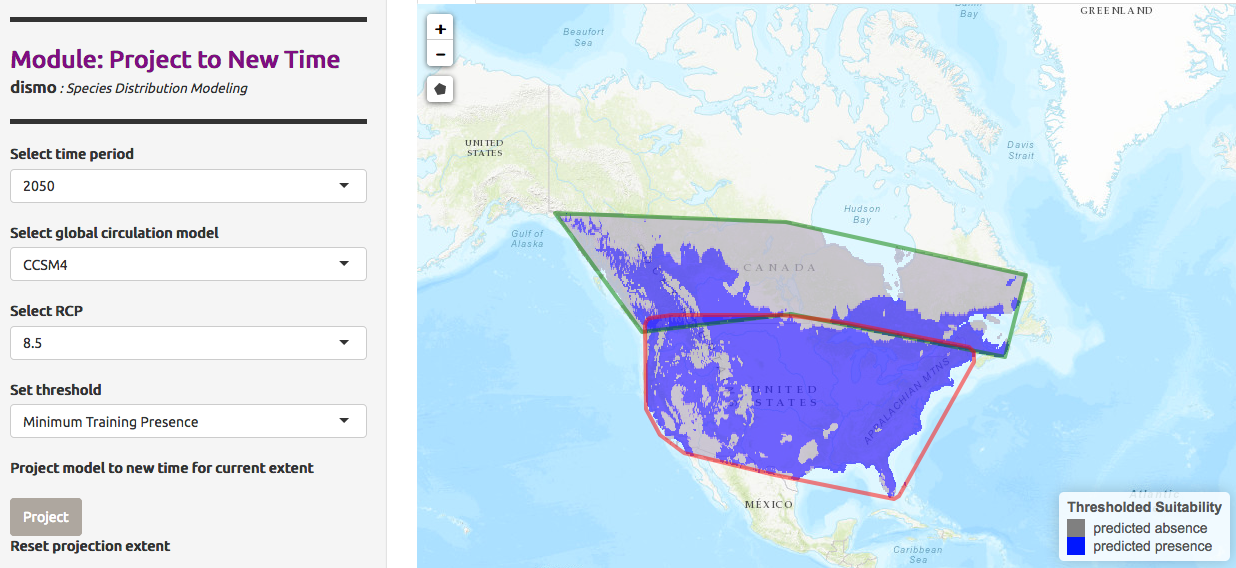
Conclusion
Following this tutorial, we have loaded a dataset of occurrences to the shiny app Wallace and modeled the distribution of Chrysemys picta (Painted turtle) with the Species Distribution Modeling (SDM) method. This allowed us to visualize it’s ecological niche and how climate change can influence it’s future distribution in North America. The saved project can be used for similar future studies.
- Predicting species distributions for conservation decisions (Guisan et al. 2013).
- BIOCLIM: the first species distribution modelling package, its early applications and relevance to most current MAXENT studies. Diversity and Distributions (Booth 2018).
- ENMeval: An R package for conducting spatially independent evaluations and estimating optimal model complexity for MAXENT ecological niche models. (Muscarella et al. 2014).
GCM Guidelines for information on Global Circulation Model (GCM), how it’s done, what is taken in consideration, and more.
You've Finished the Tutorial
Key points
Use ‘classical’ Galaxy tools in combination with Interactive tools
Identify general steps of a species distribution modeling aproach
Frequently Asked Questions
Have questions about this tutorial? Have a look at the available FAQ pages and support channelsUseful literature
Further information, including links to documentation and original publications, regarding the tools, analysis techniques and the interpretation of results described in this tutorial can be found here.
References
- Guisan, A., R. Tingley, J. B. Baumgartner, I. Naujokaitis-Lewis, P. R. Sutcliffe et al., 2013 Predicting species distributions for conservation decisions. Ecology letters 16: 1424–1435.
- Muscarella, R., P. J. Galante, M. Soley-Guardia, R. A. Boria, J. M. Kass et al., 2014 ENM eval: An R package for conducting spatially independent evaluations and estimating optimal model complexity for Maxent ecological niche models. Methods in Ecology and Evolution 5: 1198–1205.
- Booth, T., 2018 BIOCLIM–the first species distribution modelling package.
Feedback
Did you use this material as an instructor? Feel free to give us feedback on how it went.
Did you use this material as a learner or student? Click the form below to leave feedback.

Citing this Tutorial
- Elisa Michon, Yvan Le Bras, Bérénice Batut, Species distribution modeling (Galaxy Training Materials). https://training.galaxyproject.org/training-material/topics/ecology/tutorials/species-distribution-modeling/tutorial.html Online; accessed TODAY
- Hiltemann, Saskia, Rasche, Helena et al., 2023 Galaxy Training: A Powerful Framework for Teaching! PLOS Computational Biology 10.1371/journal.pcbi.1010752
- Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
@misc{ecology-species-distribution-modeling, author = "Elisa Michon and Yvan Le Bras and Bérénice Batut", title = "Species distribution modeling (Galaxy Training Materials)", year = "", month = "", day = "", url = "\url{https://training.galaxyproject.org/training-material/topics/ecology/tutorials/species-distribution-modeling/tutorial.html}", note = "[Online; accessed TODAY]" } @article{Hiltemann_2023, doi = {10.1371/journal.pcbi.1010752}, url = {https://doi.org/10.1371%2Fjournal.pcbi.1010752}, year = 2023, month = {jan}, publisher = {Public Library of Science ({PLoS})}, volume = {19}, number = {1}, pages = {e1010752}, author = {Saskia Hiltemann and Helena Rasche and Simon Gladman and Hans-Rudolf Hotz and Delphine Larivi{\`{e}}re and Daniel Blankenberg and Pratik D. Jagtap and Thomas Wollmann and Anthony Bretaudeau and Nadia Gou{\'{e}} and Timothy J. Griffin and Coline Royaux and Yvan Le Bras and Subina Mehta and Anna Syme and Frederik Coppens and Bert Droesbeke and Nicola Soranzo and Wendi Bacon and Fotis Psomopoulos and Crist{\'{o}}bal Gallardo-Alba and John Davis and Melanie Christine Föll and Matthias Fahrner and Maria A. Doyle and Beatriz Serrano-Solano and Anne Claire Fouilloux and Peter van Heusden and Wolfgang Maier and Dave Clements and Florian Heyl and Björn Grüning and B{\'{e}}r{\'{e}}nice Batut and}, editor = {Francis Ouellette}, title = {Galaxy Training: A powerful framework for teaching!}, journal = {PLoS Comput Biol} }
Funding
These individuals or organisations provided funding support for the development of this resource
Congratulations on successfully completing this tutorial!You can use Ephemeris's
shed-tools installcommand to install the tools used in this tutorial.shed-tools install [-g GALAXY] [-a API_KEY] -t <(curl https://training.galaxyproject.org/training-material/api/topics/ecology/tutorials/species-distribution-modeling/tutorial.json | jq .admin_install_yaml -r)Alternatively you can copy and paste the following YAML
--- install_tool_dependencies: true install_repository_dependencies: true install_resolver_dependencies: true tools: - name: text_processing owner: bgruening revisions: d698c222f354 tool_panel_section_label: Text Manipulation tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: text_processing owner: bgruening revisions: 0a8c6b61f0f4 tool_panel_section_label: Text Manipulation tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: spocc_occ owner: ecology revisions: f9d76a46799a tool_panel_section_label: Get Data tool_shed_url: https://toolshed.g2.bx.psu.edu/