How do I pick thresholds and parameters in my analysis? What’s a “reasonable” number, and will the world collapse if I pick the wrong one?
Objectives:
Interpret quality control plots to direct parameter decisions
Repeat analysis from matrix to clustering
Identify decision-making points
Appraise data outputs and decisions
Explain why single cell analysis is an iterative (i.e. the first plots you generate are not final, but rather you go back and re-analyse your data repeatedly) process
You’ve done all the work to make a single cell matrix, with gene counts and mitochondrial counts and buckets of cell metadata from all your variables of interest. Now it’s time to fully process our data, to remove low quality cells, to reduce the many dimensions of data that make it difficult to work with, and ultimately to try to define our clusters and to find our biological meaning and insights! There are many packages for analysing single cell data - Seurat Satija et al. 2015, Scanpy Wolf et al. 2018, Monocle Trapnell et al. 2014, Scater McCarthy et al. 2017, and so forth. We’re working with Scanpy, the python iteration of the most widely used single cell toolkit.
This tutorial is an adaptation of Filter, Plot and Explore. The workflow has been converted into a Jupyter notebook that can be ran in Galaxy through JupyterLab. The notebook runs in Python and primarily relies on the Scanpy library for performing most tasks. Running through this notebook will allow you to see and modify the code being run at each step, so feel free to experiment with the different code cells to gain a deeper understanding of the analysis process.
Get data
We’ve provided you with experimental data to analyse from a mouse dataset of fetal growth restriction Bacon et al. 2018. This is the full dataset generated from this tutorial if you used the full FASTQ files rather than the subsampled ones (see the study in Single Cell Expression Atlas and the project submission). You can find this dataset in this input history or download from Zenodo below.
You can access the data for this tutorial in multiple ways:
Your own history - If you’re feeling confident that you successfully ran a workflow on all 7 samples from the previous tutorial, and that your resulting 7 AnnData objects look right (you can compare with the answer key history), then you can use those! To avoid a million-line history, I recommend dragging the resultant datasets into a fresh history
There 3 ways to copy datasets between histories
From the original history
Click on the galaxy-gear icon which is on the top of the list of datasets in the history panel
Click on Copy Datasets
Select the desired files
Give a relevant name to the “New history”
Validate by ‘Copy History Items’
Click on the new history name in the green box that have just appear to switch to this history
Using the galaxy-columnsShow Histories Side-by-Side
Click on the galaxy-dropdown dropdown arrow top right of the history panel (History options)
Click on galaxy-columnsShow Histories Side-by-Side
If your target history is not present
Click on ‘Select histories’
Click on your target history
Validate by ‘Change Selected’
Drag the dataset to copy from its original history
Drop it in the target history
From the target history
Click on User in the top bar
Click on Datasets
Search for the dataset to copy
Click on its name
Click on Copy to current History
Importing from a history - You can import this history
Open the link to the shared history
Click on the Import this history button on the top left
Click galaxy-uploadUpload at the top of the activity panel
Select galaxy-wf-editPaste/Fetch Data
Paste the link(s) into the text field
Press Start
Close the window
Renamegalaxy-pencil the datasets Mito-counted AnnData
Check that the datatype is h5ad
Click on the galaxy-pencilpencil icon for the dataset to edit its attributes
In the central panel, click galaxy-chart-select-dataDatatypes tab on the top
In the galaxy-chart-select-dataAssign Datatype, select h5ad from “New Type” dropdown
Tip: you can start typing the datatype into the field to filter the dropdown menu
Click the Save button
Launching JupyterLab
Notebook’s can be run in Galaxy using the JupyterLab tool. JupyterLab is an interactive development environment that allows users to create interactive workflows combining code, text descriptions, and visualisations.
Interactive Jupyter Notebook. Note that on some Galaxies this is called Interactive JupyTool and notebook:
Click Run Tool
The tool will start running and will stay running permanently
This may take a moment, but once the Executed notebook in your history is orange, you are up and running!
On the left menu bar you should see the Interactive Tools Icon now. Click on it to open the Active Interactive Tools and locate the JupyterLab instance you started.
Click on your JupyterLab instance (JupyTool interactive tool)
If JupyterLab is not available on the Galaxy instance:
Data saved in interactive notebooks only persist with the instance currently running, stopping JupyterLab will result in loosing any stored data. Regularly download any important files/data!
Prepare the notebook
You have two options for running the code in this tutorial, you can either download a completed version of the notebook from the overview box at the start of this tutorial or follow along and create the notebook yourself as you go.
Hands On: Option 1: Importing notebook from file
Download the notebook from the external-linkSupporting Materials section in the overview box
Click the galaxy-uploadUpload Files button in JupyterLab
Select the downloaded notebook filter_plot_and_explore.ipynb
The notebook should appear on the left hand side, click on the file to open it (if prompted to select a kernel select Python)
Hands On: Option 2: Creating a new notebook
Under the Notebook section in the JupyterLab select Python 3
Rename the new notebook from the left-hand side panel
congratulations Congratulations! you now have JupyterLab running and can start the tutorial!
Warning: Notebook-based tutorials can give different outputs
The nature of coding pulls the most recent tools to perform tasks. This can - and often does - change the outputs of an analysis. Be prepared, as you are unlikely to get outputs identical to a tutorial if you are running it in a programming environment like a Jupyter Notebook or R-Studio. That’s ok! The outputs should still be pretty close.
Install libraries
This tutorial requies some libraries to be installed which is done below (igraph and louvain are not used directly and are just required for plotting). The -q parameter hides most of the outputs of the installation in order to make the notebook a bit cleaner. If there are any issues with the installation, then removing this parameter may give you more information about the issue.
pipinstallscanpy-q
pipinstalligraph-q
pipinstalllouvain-q
pipinstallpandas-q
We can now import the two libraries that we will be using, scanpy is the primary library that we will use and will handle all the plotting and data processing. Meanwhile, pandas is used briefly for some manual data manipulation.
importscanpyasscimportpandasaspd
Load Data
You can import files from your Galaxy history directly using the following code. This will depend on what number in your history the final annotated object is. If your object is dataset #1 in your history, then you import it with the following:
mito_counted_anndata=get(1)# get an object from Galaxy history
adata=sc.read_h5ad(mito_counted_anndata)# read in the file as h5ad object
Alternatively, if you don’t want to get the dataset from your Galaxy history, you can also download the input file from Zenodo, running the code below:
You have generated an annotated AnnData object from your raw scRNA-seq fastq files. However, you have only completed a ‘rough’ filter of your dataset - there will still be a number of ‘cells’ that are actually just background from empty droplets or simply low-quality. There will also be genes that could be sequencing artifacts or that appear with such low frequency that statistical tools will fail to analyse them. This background garbage of both cells and genes not only makes it harder to distinguish real biological information from the noise, but also makes it computationally heavy to analyse. These spurious reads take a lot of computational power to analyse! First on our agenda is to filter this matrix to give us cleaner data to extract meaningful insight from, and to allow faster analysis.
Question
What information is stored in your AnnData object? The last tool to generate this object counted the mitochondrial associated genes in your matrix. Where is that data stored?
While you are figuring that out, how many genes and cells are in your object?
Inspect the Anndata object by printing it with:
print(adata)print(adata.obs)print(adata.var)
If you examine your AnnData object, you’ll find a number of different quality control metrics for both cells (obs) and genes (var).
For instance, you can see a n_cells under var, which counts the number of cells that gene appears in.
In the obs, you have both discrete and log-based metrics for n_genes, how many genes are counted in a cell, and n_counts, how many UMIs are counted per cell. So, for instance, you might count multiple GAPDHs in a cell. Your n_counts should thus be higher than n_genes.
But what about the mitochondria?? Within the cells information obs, the total_counts_mito, log1p_total_counts_mito, and pct_counts_mito has been calculated for each cell.
You can see by printing the object that the matrix is 31178 x 35734. This is obs x vars, or rather, cells x genes, so there are 31178 cells and 35734 genes in the matrix.
Generate QC Plots
We want to filter our cells, but first we need to know what our data looks like. There are a number of subjective choices to make within scRNA-seq analysis, for instance we now need to make our best informed decisions about where to set our thresholds (more on that soon!). We’re going to plot our data a few different ways. Different bioinformaticians might prefer to see the data in different ways, and here we are only generating some of the myriad of plots you can use. Ultimately you need to go with what makes the most sense to you.
# Scatter - mito x UMIs
sc.pl.scatter(adata,x='log1p_total_counts',y='pct_counts_mito',save='-mitoxUMIs.png')
# Scatter - mito x genes
sc.pl.scatter(adata,x='log1p_n_genes_by_counts',y='pct_counts_mito',save='-mitoxgenes.png')
# Scatter - genes x UMIs
sc.pl.scatter(adata,x='log1p_total_counts',y='log1p_n_genes_by_counts',color='pct_counts_mito',save='-genesxUMIs.png')
Analysing the plots
That’s a lot of information! Let’s attack this in sections and see what questions these plots can help us answer.
Question: Batch Variation
Are there differences in sequencing depth across the samples?
Which plot(s) addresses this?
How do you interpret it?
The plot violin - batch - log will have what you’re looking for!
Open image in new tab
Figure 1: Violin - batch - log (Raw)
Keeping in mind that this is a log scale - which means that small differences can mean large differences - the violin plots probably look pretty similar.
N703 and N707 might be a bit lower on genes and counts (or UMIs), but the differences aren’t catastrophic.
The pct_counts_mito looks pretty similar across the batches, so this also looks good.
Nothing here would cause us to eliminate a sample from our analysis, but if you see a sample looking completely different from the rest, you would need to question why that is and consider eliminating it from your experiment!
Question: Biological Variables
Are there differences in sequencing depth across sex? Genotype?
Which plot(s) addresses this?
How do you interpret the sex differences?
How do you interpret the genotype differences?
Similar to above, the plots violin - sex - log and violin - genotype - log will have what you’re looking for!
Open image in new tab
There isn’t a major difference in sequencing depth across sex, I would say - though you are welcome to disagree!
It is clear there are far fewer female cells, which makes sense given that only one sample was female. Note - that was an unfortunate discovery made long after generating libraries. It’s quite hard to identify the sex of a neonate in the lab! In practice, try hard to not let such a confounding factor into your data! You could consider re-running all the following analysis without that female sample, if you wish.
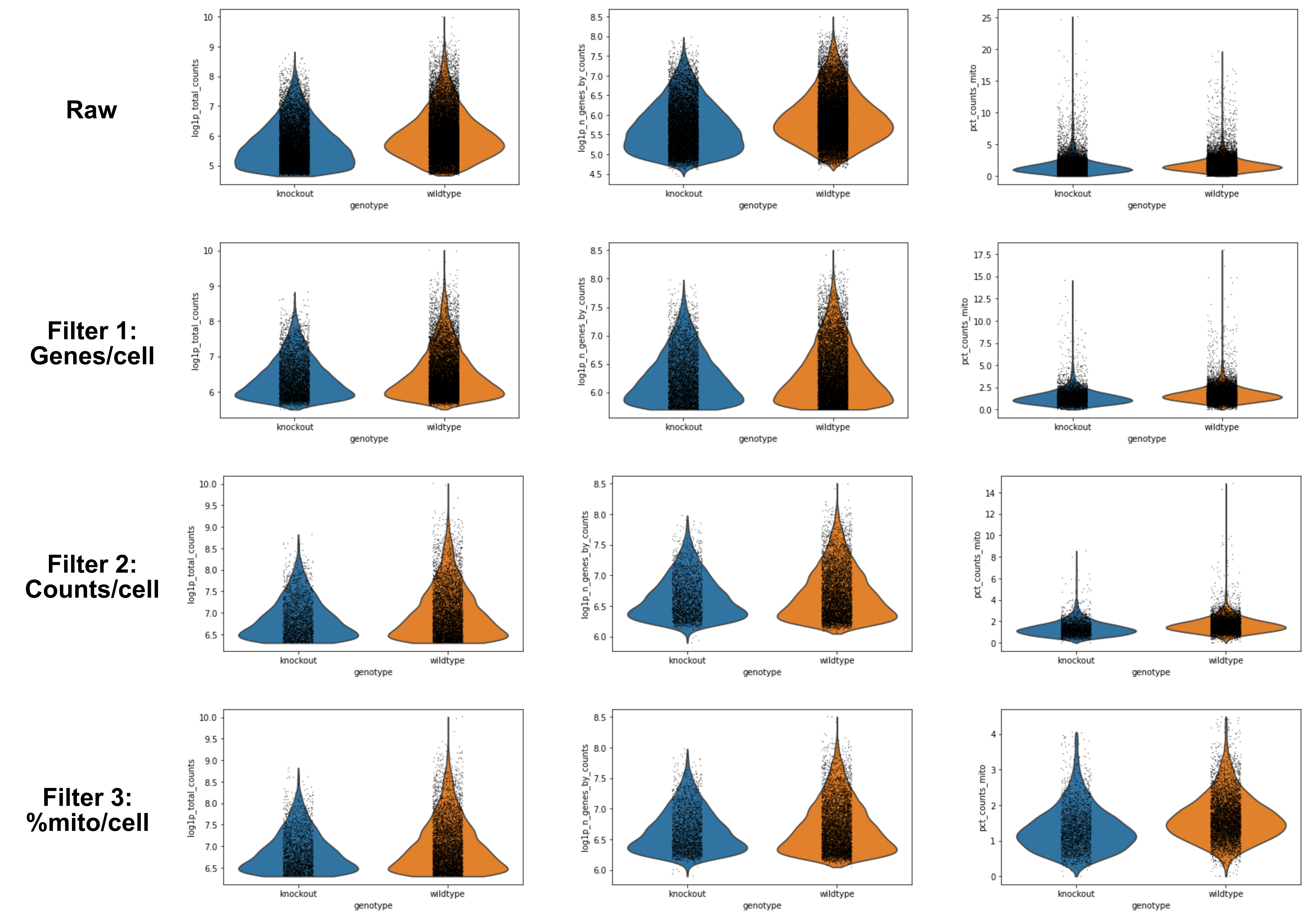
In Violin - genotype - log, however, we can see there is a difference. The knockout samples clearly have fewer genes and counts. From an experimental point of view, we can consider, does this make sense?
Would we biologically expect that those cells would be smaller or having fewer transcripts? Possibly, in this case, given that these cells were generated by growth restricted neonatal mice, and in which case we don’t need to worry about our good data, but rather keep this in mind when generating clusters, as we don’t want depth to define clusters, we want biology to!
On the other hand, it may be that those cells didn’t survive dissociation as well as the healthy ones (in which case we’d expect higher mitochondrial-associated genes, which we don’t see, so we can rule that out!).
Maybe we unluckily poorly prepared libraries for specifically those knockout samples. There are only three, so maybe those samples are under-sequenced.
So what do we do about all of this?
Ideally, we consider re-sequencing all the samples but with a higher concentration of the knockout samples in the library. Any bioinformatician will tell you that the best way to get clean data is in the lab, not the computer! Sadly, absolute best practice isn’t necessarily always a realistic option in the lab - for instance, that mouse line was long gone! - so sometimes, we have to make the best of it. There are options to try and address such discrepancy in sequencing depth. Thus, we’re going to take these samples forward and see if we can find biological insight despite the technical differences.
Now that we’ve assessed the differences in our samples, we will look at the libraries overall to identify appropriate thresholds for our analysis.
Question: Filter Thresholds: genes
What threshold should you set for log1p_n_genes_by_counts?
Which plot(s) addresses this?
What number would you pick?
Any plot with log1p_n_genes_by_counts would do here, actually! Some people prefer scatterplots to violins.
Open image in new tab
Figure 4: Scatter - mito x genes (Raw)
In Scatter - mito x genes you can see how cells with log1p_n_genes_by_counts up to around, perhaps, 5.7 (around 300 genes) often have high pct_counts_mito.
You can plot this as just n_counts and see this same trend at around 300 genes, but with this data the log format is clearer so that’s how we’re presenting it.
You could also use the violin plots to come up with the threshold, and thus also take batch into account. It’s good to look at the violins as well, because you don’t want to accidentally cut out an entire sample (i.e. N703 and N707).
Some bioinformaticians would recommend filtering each sample individually, but this is difficult in larger scale and in this case (you’re welcome to give it a go! You’d have to filter separately and then concatenate), it won’t make a notable difference in the final interpretation.
Question: Filter Thresholds: UMIs
What threshold should you set for log1p_total_counts?
Which plot(s) addresses this?
What number would you pick?
As before, any plot with log1p_total_counts will do! Again, we’ll use a scatterplot here, but you can use a violin plot if you wish!
Open image in new tab
Figure 5: Scatterplot - mito x UMIs (Raw)
We can see that we will need to set a higher threshold (which makes sense, as you’d expect more UMI’s per cell rather than unique genes!). Again, perhaps being a bit aggressive in our threshold, we might choose 6.3, for instance (which amounts to around 500 counts/cell).
In an ideal world, you’ll see a clear population of real cells separated from a clear population of debris. Many samples, like this one, are under-sequenced, and such separation would likely be seen after deeper sequencing!
Question: Filter Thresholds: mito
What threshold should you set for pct_counts_mito?
Which plot(s) addresses this?
What number would you pick?
Any plot with pct_counts_mito would do here, however the scatterplots are likely the easiest to interpret. We’ll use the same as last time.
Open image in new tab
Figure 6: Scatterplot - mito x UMIs (Raw)
We can see a clear trend wherein cells that have around 5% mito counts or higher also have far fewer total counts. These cells are low quality, will muddy our data, and are likely stressed or ruptured prior to encapsulation in a droplet. While 5% is quite a common cut-off, this is quite messy data, so just for kicks we’ll go more aggressive with a 4.5%.
In general, you must adapt all cut-offs to your data - metabolically active cells might have higher mitochondrial RNA in general, and you don’t want to lose a cell population because of a cut-off.
Applying the Thresholds
It’s now time to apply these thresholds to our data! First, a reminder of how many cells and genes are in your object: 31178 cells and 35734 genes. Let’s see how that changes each time!
If you are working in a group, you can now divide up a decision here with one control and the rest varied numbers so that you can compare results throughout the tutorials.
Control
log1p_n_genes_by_counts > 5.7
log1p_total_counts > 6.3
pct_counts_mito < 4.5%
Everyone else: Choose your own thresholds and compare results!
We will plot the raw data before applying any filters so that we can more clearly see the changes we will make.
# Raw
sc.pl.violin(adata,keys=['log1p_total_counts','log1p_n_genes_by_counts','pct_counts_mito'],groupby='genotype',save='-raw.png')
The only part that seems to change is the log1p_n_genes_by_counts. You can see a flatter bottom to the violin plot - this is the lower threshold set. Ideally, this would create a beautiful violin plot because there would be a clear population of low-gene number cells. Sadly not the case here, but still a reasonable filter.
In the printed AnnData information, you can see you now have 17,040 cells x 35,734 genes.
We will focus on the log1p_total_counts as that shows the biggest change. Similar to above, the bottom of the violin shape has flattered due to the threshold.
In the printed AnnData information, you can see you now have 8,678 cells x 35,734 genes.
Fantastic work! However, you’ve now removed a whole heap of cells, and since the captured genes are sporadic (i.e. a small percentage of the overall transcriptome per cell) this means there are a number of genes in your matrix that are currently not in any of the remaining cells. Genes that do not appear in any cell, or even in only 1 or 2 cells, will make some analytical tools break and overall will not be biologically informative. So let’s remove them! Note that 3 is not necessarily the best number, rather it is a fairly conservative threshold. You could go as high as 10 or more.
If you are working in a group, you can now divide up a decision here with one control and the rest varied numbers so that you can compare results throughout the tutorials.
min_cells = 3
Everyone else: Choose your own thresholds and compare results! Note if you go less than 3 (or even remove this step entirely), future tools are likely to fail due to empty gene data.
In practice, you’ll likely choose your thresholds then set up all these filters to run without checking plots in between each one. But it’s nice to see how they work!
Using the final filtered_object, we can summarise the results of our filtering:
Description
Genes
Raw
31178
35734
Filter genes/cell
17040
35734
Filter counts/cell
8678
35734
Filter mito/cell
8605
35734
Filter cells/gene
8605
15395
congratulations Congratulations! You have filtered your object! Now it should be a lot easier to analyse.
Processing
So currently, you have a matrix that is 8605 cells by 15395 genes. This is still quite big data. We have two issues here - firstly, you already know there are differences in how many transcripts and genes have been counted per cell. This technical variable can obscure biological differences. Secondly, we like to plot things on x/y plots, so for instance Gapdh could be on one axis, and Actin can be on another, and you plot cells on that 2-dimensional axis based on how many of each transcript they possess. While that would be fine, adding in a 3rd dimension (or, indeed, in this case, 15393 more dimensions), is a bit trickier! So our next steps are to transform our big data object into something that is easy to analyse and easy to visualise.
Normalisation helps reduce the differences between gene and UMI counts by fitting total counts to 10,000 per cell. The inherent log-transform (by log(count+1)) aligns the gene expression level better with a normal distribution. This is fairly standard to prepare for any future dimensionality reduction.
Now we need to look at reducing our gene dimensions. We have loads of genes, but not all of them are different from cell to cell. For instance, housekeeping genes are defined as not changing much from cell to cell, so we could remove these from our data to simplify the dataset. We will flag genes that vary across the cells for future analysis.
output_h5ad=sc.pp.log1p(output_h5ad,copy=True)# below function requires log scaled data
sc.pp.highly_variable_genes(output_h5ad)
Next up, we’re going to scale our data so that all genes have the same variance and a zero mean. This is important to set up our data for further dimensionality reduction. It also helps negate sequencing depth differences between samples, since the gene levels across the cells become comparable. Note, that the differences from scaling etc. are not the values you have at the end - i.e. if your cell has average GAPDH levels, it will not appear as a ‘0’ when you calculate gene differences between clusters.
congratulations Congratulations! You have processed your object!
Comment
At this point, we might want to remove or regress out the effects of unwanted variation on our data. A common example of this is the cell cycle, which can affect which genes are expressed and how much material is present in our cells. If you’re interested in learning how to do this, then you can move over to the Removing the Effects of the Cell Cycle tutorial now – then return here to complete your analysis.
Preparing coordinates
We still have too many dimensions. Transcript changes are not usually singular - which is to say, genes were in pathways and in groups. It would be easier to analyse our data if we could more easily group these changes.
Principal components
Principal components are calculated from highly dimensional data to find the most spread in the dataset. So in our, 1982 highly variable gene dimensions, there will be one line (axis) that yields the most spread and variation across the cells. That will be our first principal component. We can calculate the first x principal components in our data to drastically reduce the number of dimensions.
Comment: 1982???
Where did the 1982 come from?
The quickest way to figure out how many highly variable genes you have, in my opinion, is to re-run sc.pp.highly_variable_genes function with the added parameter subset=True, therefore: sc.pp.highly_variable_genes(output_h5ad, subset=True). This subsetting removes any nonvariable genes.
Then you can print(output_h5ad) and you’ll see only 1982 genes. The following processing steps will use only the highly variable genes for their calculations, but depend on keeping all genes in the object. Thus, please use the original output of your sc.pp.highly_variable_genes function with far more than 1982 genes!, currently stored as scaled_data.
Warning: Check your AnnData object!
Run print(scaled_data)
Your AnnData object should have far more than 1982 genes in it (if you followed our settings and tool versions, you’d have a matrix 8605 × 15395 (cells x genes). Make sure to use that AnnData object output from FindVariableGenes, rather than the 1982 from your testing in the section above labelled ‘1982’.
We can see that there is really not much variation explained past component 19. So we might save ourselves a great deal of time and muddied data by focusing on the top 20 PCs.
Neighborhood graph
We’re still looking at around 20 dimensions at this point. We need to identify how similar a cell is to another cell, across every cell across these dimensions. For this, we will use the k-nearest neighbor (kNN) graph, to identify which cells are close together and which are not. The kNN graph plots connections between cells if their distance (when plotted in this 20 dimensional space!) is amonst the k-th smallest distances from that cell to other cells. This will be crucial for identifying clusters, and is necessary for plotting a UMAP. From UMAP developers: “Larger neighbor values will result in more global structure being preserved at the loss of detailed local structure. In general this parameter should often be in the range 5 to 50, with a choice of 10 to 15 being a sensible default”.
If you are working in a group, you can now divide up a decision here with one control and the rest varied numbers so that you can compare results throughout the tutorials.
Control
Number of PCs to use = 20
Maximum number of neighbours used = 15
Everyone else: Use the PC variance plot to pick your own PC number, and choose your own neighbour maximum as well!
Two major visualisations for this data are tSNE and UMAP. We must calculate the coordinates for both prior to visualisation. For tSNE, the parameter perplexity can be changed to best represent the data, while for UMAP the main change would be to change the kNN graph above itself, by changing the neighbours.
If you are working in a group, you can now divide up a decision here with one control and the rest varied numbers so that you can compare results throughout the tutorials.
Control
Perplexity = 30
Everyone else: Choose your own perplexity, between 5 and 50!
congratulations Congratulations! You have prepared your object and created neighborhood coordinates. We can now use those to call some clusters!
Cell clusters & gene markers
Question
Let’s take a step back here. What is it, exactly, that you are trying to get from your data? What do you want to visualise, and what information do you need from your data to gain insight?
Really we need two things - firstly, we need to make sure our experiment was set up well. This is to say, our biological replicates should overlap and our variables should, ideally, show some difference. Secondly, we want insight - we want to know which cell types are in our data, which genes drive those cell types, and in this case, how they might be affected by our biological variable of growth restriction. How does this affect the developing cells, and what genes drive this? So let’s add in information about cell clusters and gene markers!
Finally, let’s identify clusters! Unfortunately, it’s not as majestic as biologists often think - the maths doesn’t necessarily identify true cell clusters. Every algorithm for identifying cell clusters falls short of a biologist knowing their data, knowing what cells should be there, and proving it in the lab. Sigh. So, we’re going to make the best of it as a starting point and see what happens! We will define clusters from the kNN graph, based on how many connections cells have with one another. Roughly, this will depend on a resolution parameter for how granular you want to be.
Oh yes, yet another decision! Single cell analysis is sadly not straight forward.
Control
Resolution, high value for more and smaller clusters = 0.6
Everyone else: Pick your own number. If it helps, this sample should have a lot of very similar cells in it. It contains developing T-cells, so you aren’t expecting massive differences between cells, like you would in, say, an entire embryo, with all sorts of unrelated cell types.
But we are also interested in differences across genotype, so let’s also check that (note that in this case, it’s turning it almost into bulk RNA-seq, because you’re comparing all cells of a certain genotype against all cells of the other)
Note: The function rank_genes_groups does not return a DataFrame that we can use but instead metadata about the marker table, so first we need to construct the marker table using this generated metadata. This is done using the following function, however it’s not too important to understand what this code does!
Now, there’s a small problem here, which is that if you inspect the output marker tables (above tables), you won’t see gene names, you’ll see Ensembl IDs. While this is a more bioinformatically accurate way of doing this (not every ID has a gene name!), we might want to look at more well-recognised gene names, so let’s pop some of that information in!
# Join two datasets
cluster_joined=pd.merge(cluster_marker_table,markers_cluster.var,left_on='genes',right_on='ID')genotype_joined=pd.merge(genotype_marker_table,markers_genotype.var,left_on='genes',right_on='ID')display(cluster_joined.head(5))display(genotype_joined.head(5))
# Cut columns from tables
cluster_markers_named=cluster_joined[['cluster','ref','rank','genes','Symbol','scores','logfoldchanges','pvals','pvals_adj']]genotype_markers_named=genotype_joined[['cluster','ref','rank','genes','Symbol','scores','logfoldchanges','pvals','pvals_adj']]display(cluster_markers_named.head(5))display(genotype_markers_named.head(5))
Well done! It’s time for the best bit, the plotting!
Plotting!
It’s time! Let’s plot it all! But first, let’s pick some marker genes from the markers_cluster list that you made as well. I’ll be honest, in practice, you’d now be spending a lot of time looking up what each gene does (thank you google!). There are burgeoning automated-annotation tools, however, so long as you have a good reference (a well annotated dataset that you’ll use as the ideal). In the mean time, let’s do this the old-fashioned way, and just copy a bunch of the markers in the original paper.
congratulations Congratulations! You now have plots galore!
Insights into the beyond
Now it’s the fun bit! We can see where genes are expressed, and start considering and interpreting the biology of it. At this point, it’s really about what information you want to get from your data - the following is only the tip of the iceberg. However, a brief exploration is good, because it may help give you ideas going forward with for your own data. Let us start interrogating our data!
Biological Interpretation
Question: Appearance is everything
Which visualisation is the most useful for getting an overview of our data, pca, tsne, or umap?
Figure 12: Louvain clustering by dimension reduction
You can see why a PCA is generally not enough to see clusters in samples - keep in mind, you’re only seeing components 1 and 2! - and therefore why the tSNE and UMAP visualisation dimensionality reductions are so useful. But there is not necessarily a clear winner between tSNE and UMAP, but I think UMAP is slightly clearer with its clusters, so we’ll stick with that for the rest of the analysis.
Note that the cluster numbering is based on size alone - clusters 0 and 1 are not necessarily related, they are just the clusters containing the most cells. It would be nice to know what exactly these cells are. This analysis (googling all of the marker genes, both checking where the ones you know are as well as going through the marker tables you generated!) is a fun task for any individual experiment, so we’re going to speed past that and nab the assessment from the original paper!
Clusters
Marker
Cell type
4
Il2ra
Double negative (early T-cell)
0,1,2,6
Cd8b1, Cd8a, Cd4
Double positive (middle T-cell)
5
Cd8b1, Cd8a, Cd4 - high
Double positive (late middle T-cell)
3
Itm2a
Mature T-cell
7
Hba-a1
RBCs (as impurity here)
-
Aif1
Macrophages
The authors weren’t interested in further annotation of the DP cells, so neither are we. Sometimes that just happens. The maths tries to call similar (ish) sized clusters, whether it is biologically relevant or not. Or, the question being asked doesn’t really require such granularity of clusters.
If you have deviated from any of the original parameters in this tutorial, you will likely have a different number of clusters. You will, therefore, need to change the categories parameter in rename_categories accordingly. Best of luck!
Annotating Clusters
As mentioned at the beginning of the tutorial, you might not get outputs identical to a tutorial if you are running it in a programming environment, but the outputs should still be pretty close. However, you have to double check if the categories (ie. cell types) in the example below correspond to the identified cluster numbers based on gene expression. You might need to change the order of assigned cell types in the categories parameter to match the cluster numbers identified by louvain.
# Add meaningful names to each category
markers_cluster.rename_categories(key='louvain',categories=['DP-M4','DP-M3','T-mat','DN','DP-M2','DP-M1','DP-L','RBCs'])# categories (cell types) correspond to the identified cluster numbers, ie. [0, 1, 2,...,7]
# Copy AnnData object
markers_cluster_copy=markers_cluster.copy()# Rename 'louvain' column
markers_cluster_copy.obs=markers_cluster_copy.obs.rename(columns={'louvain':'cell_type'})# Scanpy - plot updated object
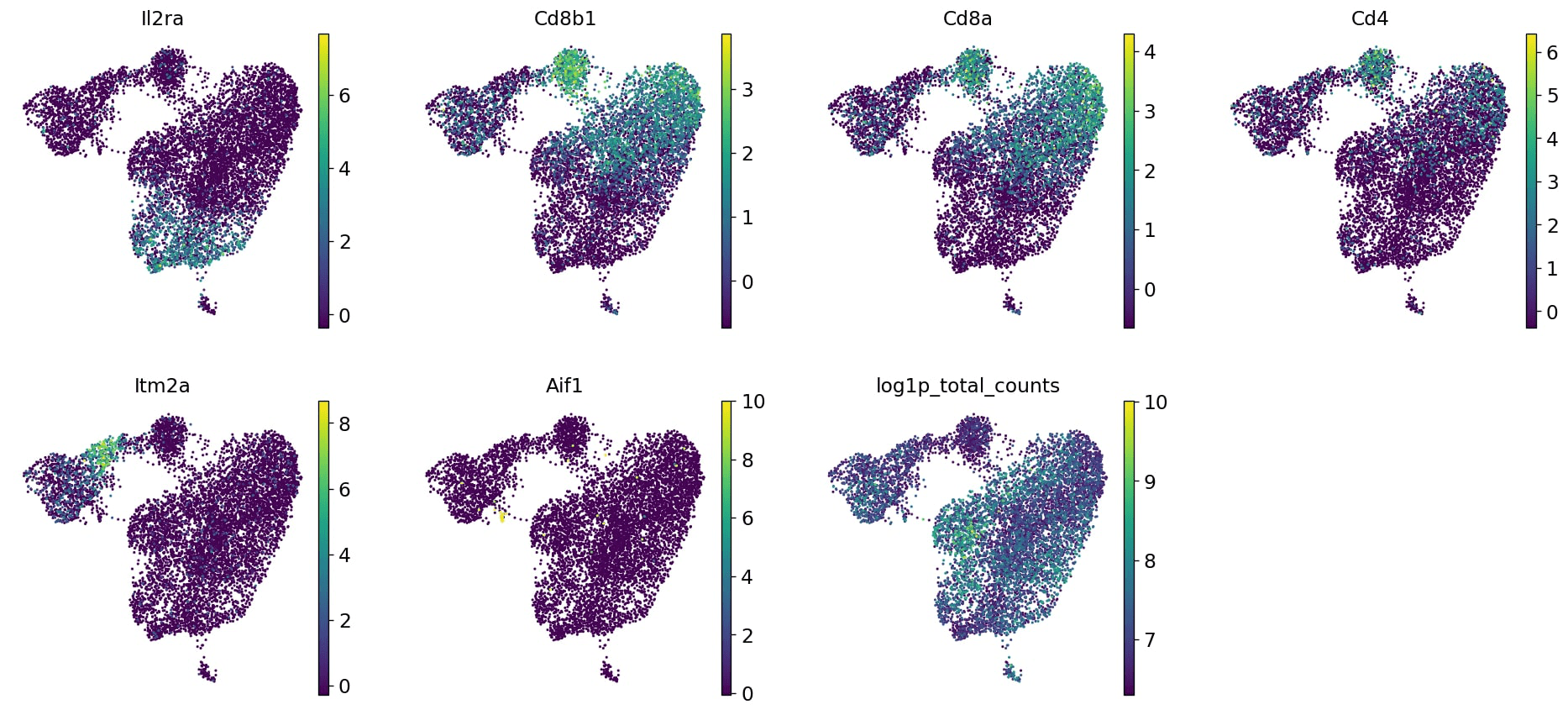
sc.pl.embedding(markers_cluster_copy,basis='umap',color=['cell_type','sex','batch','genotype','Il2ra','Cd8b1','Cd8a','Cd4','Itm2a','Aif1','Hba-a1','log1p_total_counts'],gene_symbols='Symbol',use_raw=False,save='-annotated.png')
We can see that DP-L, which seems to be extending away from the DP-M bunch, as well as the mature T-cells (or particularly the top half) are missing some knockout cells. Perhaps there is some sort of inhibition here? INTERESTING! What next? We might look further at the transcripts present in both those populations, and perhaps also look at the genotype marker table… So much to investigate! But before we set you off to explore to your heart’s delight, let’s also look at this a bit more technically.
Technical Assessment
Is our analysis real? Is it right? Well, we can assess that a little bit.
While some shifts are expected and nothing to be concerned about, DP-L looks to be mainly comprised of N705. There might be a bit of batch effect, so you could consider using batch correction on this dataset. However, if we focus our attention on the other cluster - mature T-cells - where there is batch mixing, we can still assess this biologically even without batch correction.
Additionally, we will also look at the confounding effect of sex.
We note that the one female sample - unfortunately one of the mere three knockout samples - seems to be distributed in the same areas as the knockout samples at large, so luckily, this doesn’t seem to be a confounding factor and we can still learn from our data. Ideally, this experiment would be re-run with either more female samples all around or swapping out this female from the male sample.
Question: Depth effect
Are there any clusters or differences being driven by sequencing depth, a technical and random factor?
Eureka! This explains the odd DP shift between wildtype and knockout cells - the left side of the DP cells simply have a higher sequencing depth (UMIs/cell) than the ones on the right side. Well, that explains some of the sub-cluster that we’re seeing in that splurge. Importantly, we don’t see that the DP-L or (mostly) the mature T-cell clusters are similarly affected. So, whilst again, this variable of sequencing depth might be something to regress out somehow, it doesn’t seem to be impacting our dataset. The less you can regress/modify your data, in general, the better - you want to stay as true as you can to the raw data, and only use maths to correct your data when you really need to (and not to create insights where there are none!).
Question: Sample purity
Do you think we processed these samples well enough?
We have seen in the previous images that these clusters are not very tight or distinct, so we could consider stronger filtering. Additionally, hemoglobin - a red blood cell marker that should NOT be found in T-cells - appears throughout the entire sample in low numbers. This suggests some background in the media the cells were in, and we might consider in the wet lab trying to get a purer, happier sample, or in the dry lab, techniques such as SoupX or others to remove this background. Playing with filtering settings (increasing minimum counts/cell, etc.) is often the place to start in these scenarios.
Question: Clustering resolution
Do you think the clustering is appropriate? i.e. are there single clusters that you think should be separate, and multiple clusters that could be combined?
Important to note, lest all bioinformaticians combine forces to attack the biologists: just because a cluster doesn’t look like a cluster by eye is NOT enough to say it’s not a cluster! But looking at the biology here, we struggled to find marker genes to distinguish the DP population, which we know is also affected by depth of sequencing. That’s a reasonable argument that DP-M1, DP-M2, and DP-M3 might not be all that different. Maybe we need more depth of sequencing across all the DP cells, or to compare these explicitly to each other (consider variations on FindMarkers!). However, DP-L is both seemingly leaving the DP cluster and also has fewer knockout cells, so we might go and look at what DP-L is expressing in the marker genes. If we look at T-mat further, we can see that its marker gene - Itm2a - is only expressed in half of the cluster. You might consider sub-clustering this to investigate further, either through changing the resolution or through analysing this cluster alone.
If we look at the differences between genotypes alone (so the pseudo-bulk), we can see that most of the genes in that list are actually ribosomal. This might be a housekeeping background, this might be cell cycle related, this might be biological, or all three. You might consider investigating the cycling status of the cells, or even regressing this out (which is what the authors did).
Ultimately, there are quite a lot ways to analyse the data, both within the confines of this tutorial (the many parameters that could be changed throughout) and outside of it (batch correction, sub-clustering, cell-cycle scoring, inferred trajectories, etc.) Most analyses will still yield the same general output, though: there are fewer knockout cells in the mature T-cell population.
congratulations Congratulations! You have interpreted your plots in several important ways!
Export your data, and notebook, and figures
It’s now time to export your data! First, we need to get Jupyter to see it as a file.
adata.write('MarkersCluster.h5ad')
Now you can export it.
put("MarkersCluster.h5ad")
To export your notebook to your Galaxy history, you can use the following. Change the text to be your notebook name. Do not use spaces!
put("name_of_jupyter_notebook.ipynb")
Want to export some plots? Choose any (or all) of the plots you saved as files in the folder at the left and put their titles in the following. You can run multiple exports at the same time.
congratulations Congratulations! You’ve made it to the end!
In this tutorial, you moved from technical processing to biological exploration. By analysing real data - both the exciting and the messy! - you have, hopefully, experienced what it’s like to analyse and question a dataset, potentially without clear cut-offs or clear answers. If you were working in a group, you each analysed the data in different ways, and most likely found similar insights. One of the biggest problems in analysing scRNA-seq is the lack of a clearly defined pathway or parameters. You have to make the best call you can as you move through your analysis, and ultimately, when in doubt, try it multiple ways and see what happens!
If, for some reasons anything didn’t work in Galaxy JupyterLab environment, please don’t get discouraged - we prepared a Google Colab notebook version for you as a backup so that you can enjoy the tutorial no matter what!
You've Finished the Tutorial
Please also consider filling out the Feedback Form as well!
Key points
Single cell data is huge, and must have its many (# genes) dimensions reduced for analysis
Analysis is more subjective than we think, and biological understanding of the samples as well as many iterations of analysis are important to give us our best change of attaining real biological insights
Frequently Asked Questions
Have questions about this tutorial? Have a look at the available FAQ pages and support channels
Further information, including links to documentation and original publications, regarding the tools, analysis techniques and the interpretation of results described in this tutorial can be found here.
References
Bacon, W. A., R. S. Hamilton, Z. Yu, J. Kieckbusch, D. Hawkes et al., 2018 Single-Cell Analysis Identifies Thymic Maturation Delay in Growth-Restricted Neonatal Mice. Frontiers in Immunology 9: 10.3389/fimmu.2018.02523
Feedback
Did you use this material as an instructor? Feel free to give us feedback on how it went.
Did you use this material as a learner or student? Click the form below to leave feedback.
Hiltemann, Saskia, Rasche, Helena et al., 2023 Galaxy Training: A Powerful Framework for Teaching! PLOS Computational Biology 10.1371/journal.pcbi.1010752
Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
@misc{single-cell-scrna-case-jupyter_basic-pipeline,
author = "Morgan Howells and Wendi Bacon",
title = "Filter, plot and explore single-cell RNA-seq data with Scanpy (Python) (Galaxy Training Materials)",
year = "",
month = "",
day = "",
url = "\url{https://training.galaxyproject.org/training-material/topics/single-cell/tutorials/scrna-case-jupyter_basic-pipeline/tutorial.html}",
note = "[Online; accessed TODAY]"
}
@article{Hiltemann_2023,
doi = {10.1371/journal.pcbi.1010752},
url = {https://doi.org/10.1371%2Fjournal.pcbi.1010752},
year = 2023,
month = {jan},
publisher = {Public Library of Science ({PLoS})},
volume = {19},
number = {1},
pages = {e1010752},
author = {Saskia Hiltemann and Helena Rasche and Simon Gladman and Hans-Rudolf Hotz and Delphine Larivi{\`{e}}re and Daniel Blankenberg and Pratik D. Jagtap and Thomas Wollmann and Anthony Bretaudeau and Nadia Gou{\'{e}} and Timothy J. Griffin and Coline Royaux and Yvan Le Bras and Subina Mehta and Anna Syme and Frederik Coppens and Bert Droesbeke and Nicola Soranzo and Wendi Bacon and Fotis Psomopoulos and Crist{\'{o}}bal Gallardo-Alba and John Davis and Melanie Christine Föll and Matthias Fahrner and Maria A. Doyle and Beatriz Serrano-Solano and Anne Claire Fouilloux and Peter van Heusden and Wolfgang Maier and Dave Clements and Florian Heyl and Björn Grüning and B{\'{e}}r{\'{e}}nice Batut and},
editor = {Francis Ouellette},
title = {Galaxy Training: A powerful framework for teaching!},
journal = {PLoS Comput Biol}
}
Congratulations on successfully completing this tutorial!
Do you want to extend your knowledge?
Follow one of our recommended follow-up trainings:
Questions:

Open image in new tab
Open image in new tab
Open image in new tab
Open image in new tab
Open image in new tab
Open image in new tab
Open image in new tab
Open image in new tab
 Open image in new tab
Open image in new tab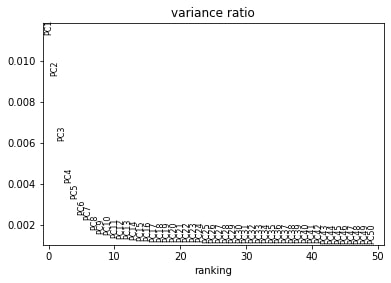 Open image in new tab
Open image in new tabOpen image in new tab
 Open image in new tab
Open image in new tab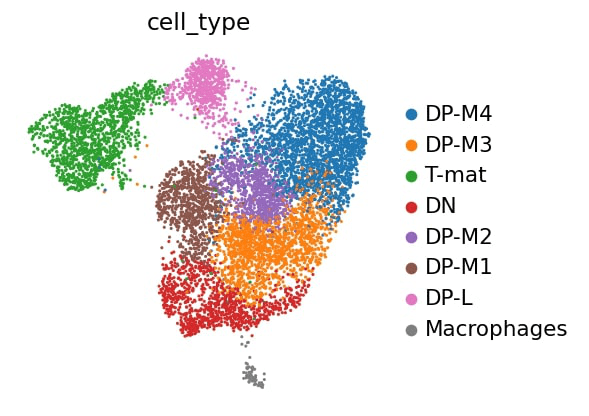 Open image in new tab
Open image in new tabOpen image in new tab
Open image in new tab
Open image in new tab
Open image in new tab
Open image in new tab
Open image in new tab
