This tutorial aims to teach how to use functionalities of the EML Assembly Line R package to produce rich metadata using the Ecological Metadata Language (EML) international metadata standard. Here, we will notably propose a concrete example on how to use Galaxy Ecology tools to create, evaluate and modify EML metadata content using both EML Assemby Line metadata template tabular files, easily readable and editable by humans, and XML file, devoted to machine.
1] How can EML Assembly Line functionalities help producing rich metadata easily?
A major gap when a researcher is writing metadata documents is the fact that metadata international standards often use formats not really human readable and/or editable as XML or JSON. To answer this issue, [Environmental Data Initiative](https://edirepository.org/) (EDI) through the EML Assembly Line R package propose to generate intermediate metadata template files using classical tabular text format.
Another major issue regarding metadata fill in, is the fact that one need to take a lot of time to write, and often rewrite, metadata elements who can be already filled using automatic inferences or use of webservices. Here again, Environmental Data Initiaitve (EDI) through the EML Assembly Line R package propose to generate automatically information related to data attributes, geographic coverage, taxonomic coverage, using the content of provided datafiles.
Finally, through the MetaShARK R Shiny app, an R Shiny app in beta version for test, created by the french biodiversity data hub research infrastructure (Pôle national de données de Biodiversité (PNDB)), user can use a graphical user interface to apply the EML Assembly Line workflow and benefit from some additionnal functionnalities as:
Capacity to associate terminological resources terms coming from Bioportal ontologies to data attributes as keywords using CEDAR API
Automatic fill in of personal information using ORCID API
Automatic production of a data paper draft
Comment: What is a Data Paper ?
According to the GBIF (Global Biodiversity Information Facility),
A data paper is a peer reviewed document describing a dataset, published in a peer reviewed journal. It takes effort to prepare, curate and describe data.
Data papers provide recognition for this effort by means of a scholarly article.
2] Get data to describe 💾📂
Hands On: Data Upload
Create a new history for this tutorial. You can name it “EML assembly Line tutorial” for example
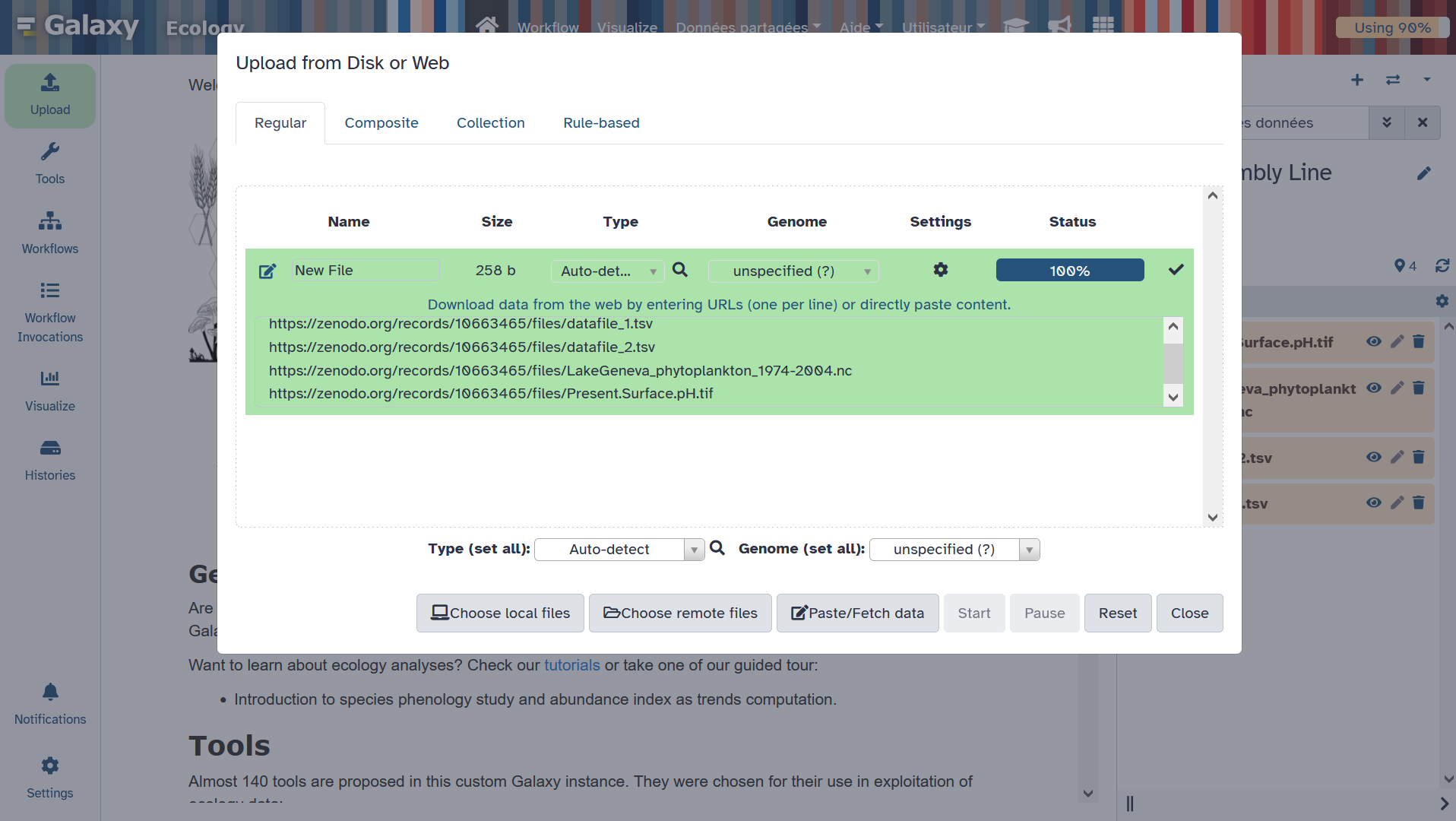
Download all files on your local computer from Zenodo: https://zenodo.org/api/records/10663465/files-archive. It is neccessary as for now, MetaShARK is deployed from Galaxy but without having a possibility to directly populate MetaShARK app with datafiles from Galaxy. You will thus then have to upload manually data files from your local computer to MetaShARK.
Unzip the donwloaded archive so you can access each file independently
Import tsv, netcdf and geotiff data files directly from Zenodo so it can be used on some steps of the tutorial.
-> Training Data for “Creating metadata using Ecological Metadata Language (EML) standard with EML Assembly Line functionalities” Galaxy tutorial:
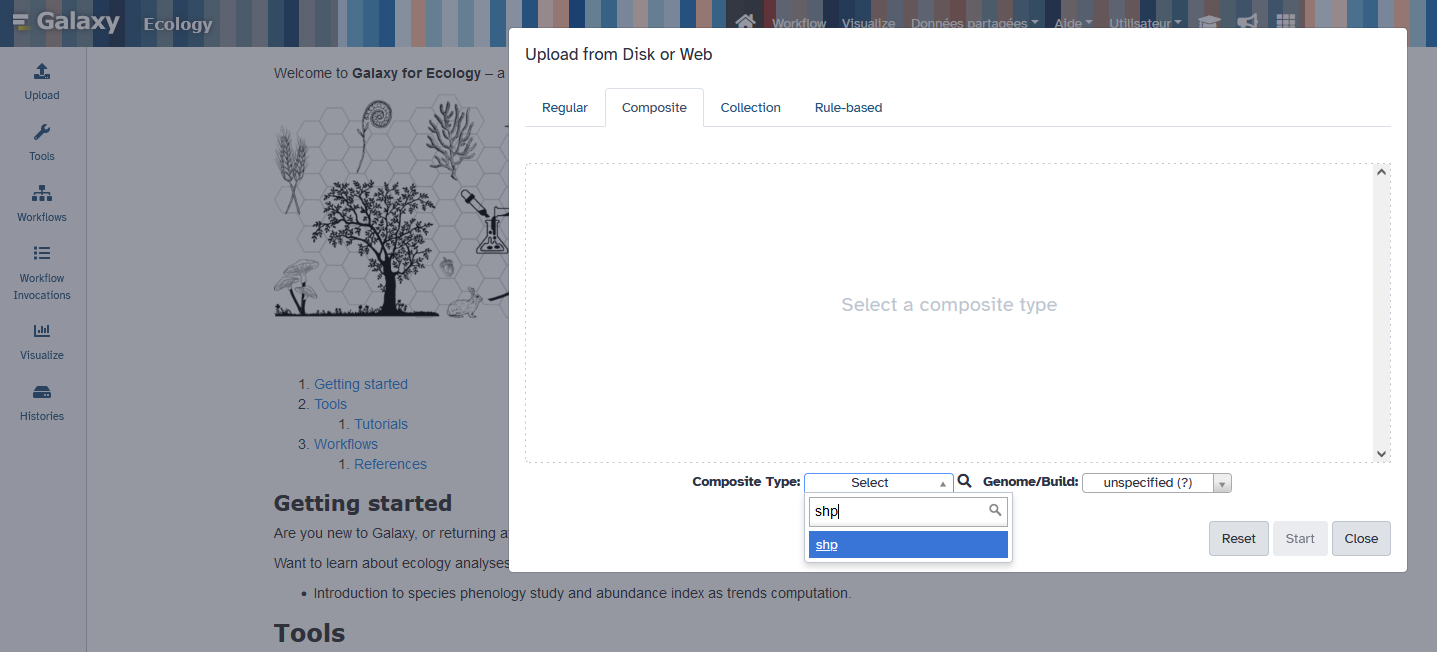
Import shapefile related files into Galaxy using the Galaxy upload tool, then on the “composite” tab, specifying “shp” composite type, then uploading .dbf, .shp and .shx files on the dedicated spaces.
3] MetaShARK 🦈 : Write rapidly an EML document through a work in progress interactive app
To deploy a MetaShARK app, you can go to the Galaxy tool MetaShARK and click “Execute”. Then, you have to wait the launch of the app, and when ready to be used, you will see the message “There is an InteractiveTool result view available,” with an hyperlink on the “Open” statement allowing you to reach the app clicking on it.
Comment: WARNING
🚧 Note that MetaShARK R shiny app is in beta version. You can thus encounter issues using it!
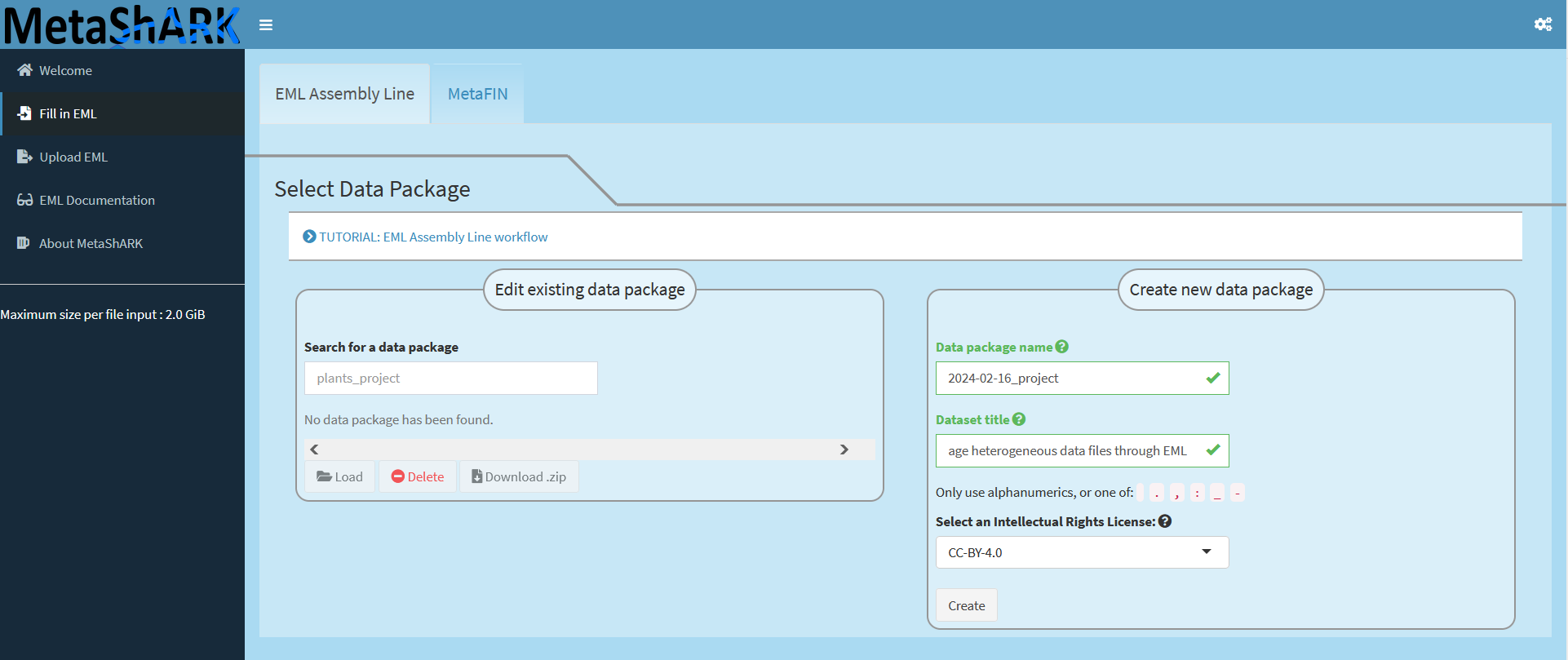
When oppening MetaShARK, you will have an interface looking like this :
To start creating metadata, you need to reach the Fill in EML module, then specify or complete the automatic Data package name and mention the Dataset title. Here a title can be “Manage heterogeneous data files through EML”. Finally, you can choose an open licence between CC-BY-4.0, default, or CC0 then click on “Create”.
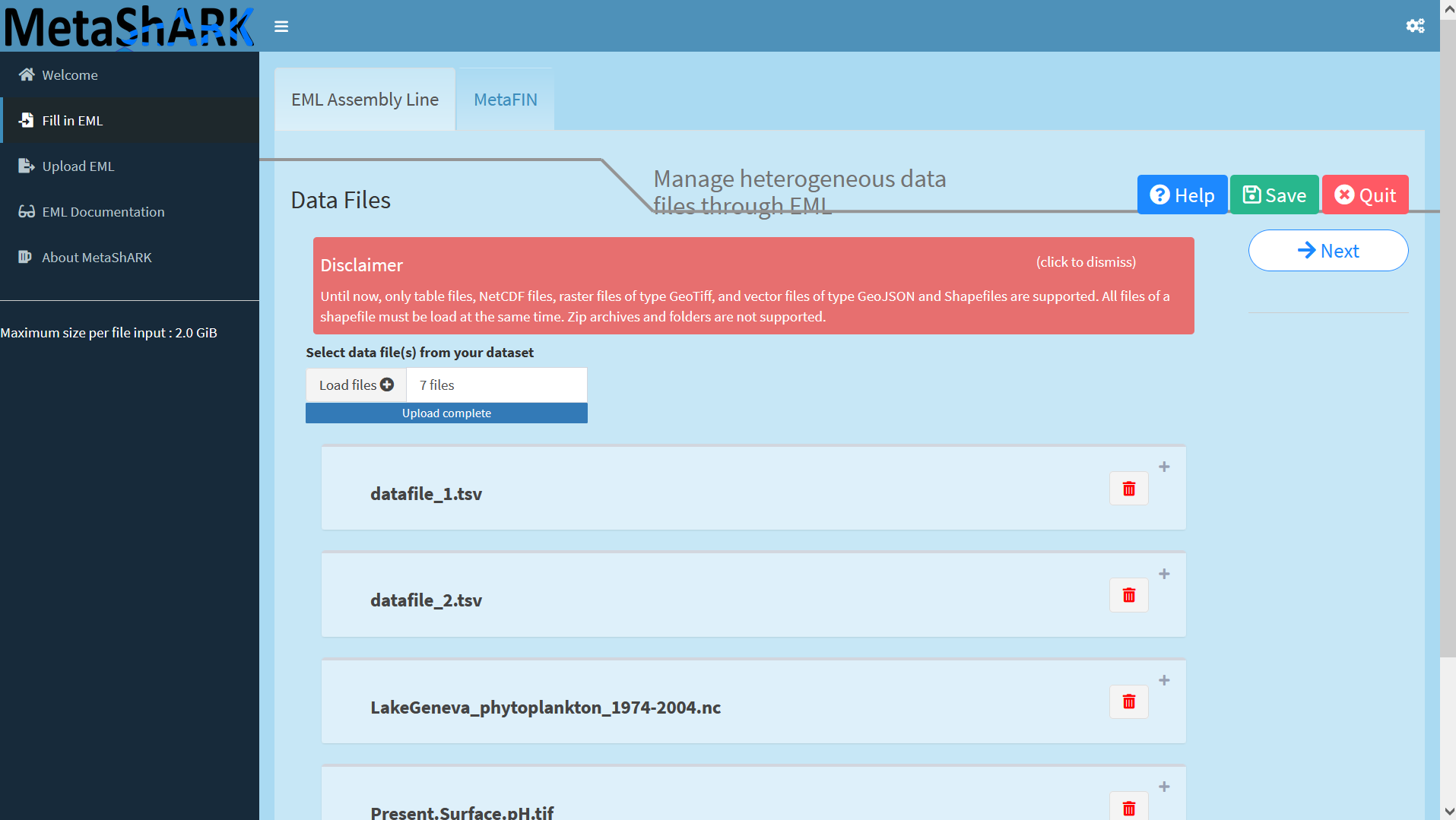
Then you can upload datafiles. Here, you can import these files from the downloaded Zenodo archive (link : https://zenodo.org/api/records/10663465/files-archive):
📁 List of datasets :
datafile_1.tsv
datafile_2.tsv
LakeGeneva_phytoplankton_1974-2004.nc
Present.Surface.pH.tif
02_Ref.shp
02_Ref.shx
02_Ref.dbf
Comment: NOTE
The folder contains many files with different extensions but MetaShark will normally recognise several types of file extension (notably .tsv for tabulated text files, shapefiles, .geotiff and .geojson)!
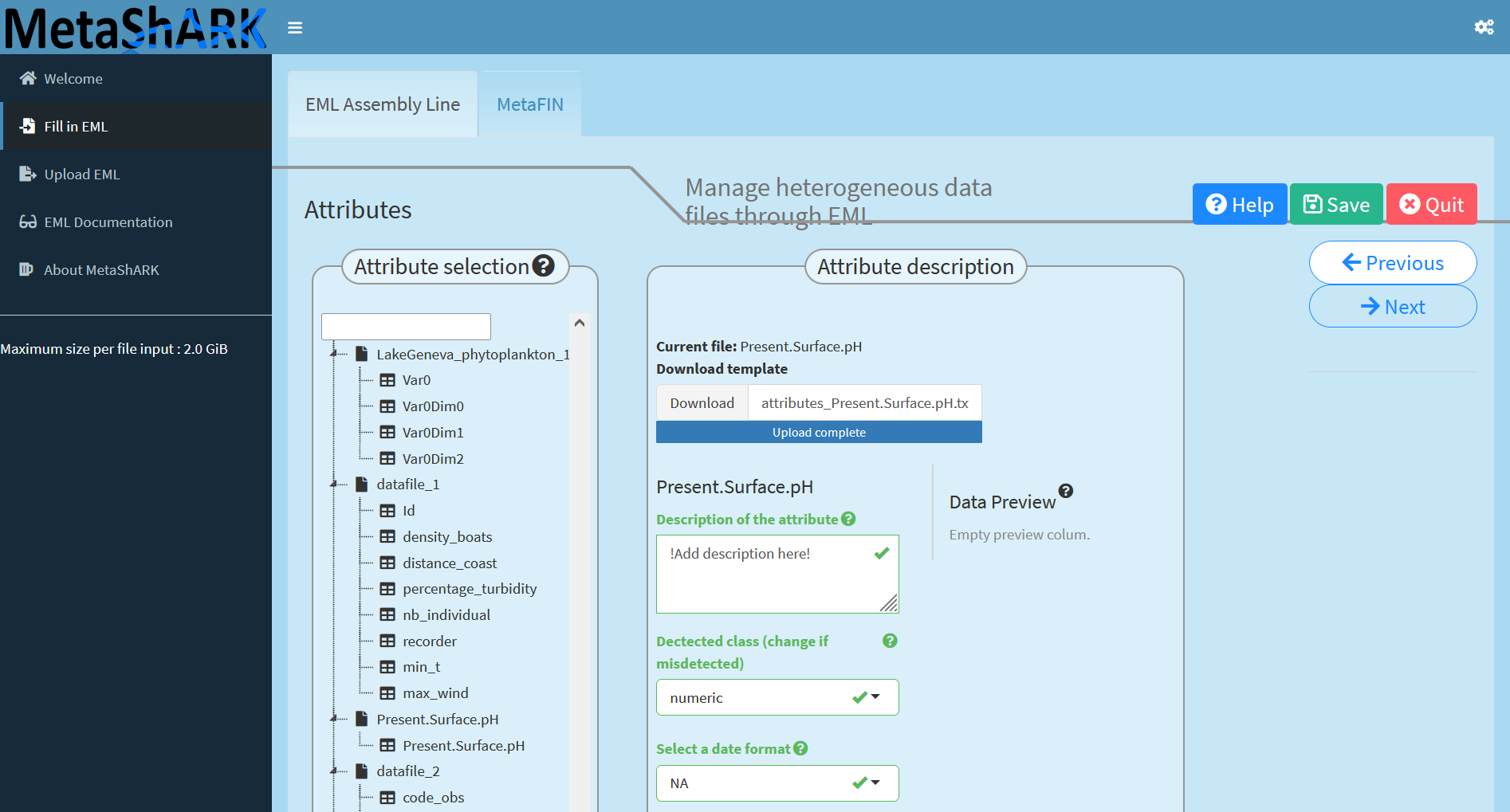
MetaShARK will normally guess that the three `02_Ref` files are representing a uniq shapefile. MetaShARK will normally guess each data type and infer list of attributes for each file but the geotiff `Present.Surface.pH.tif` one. So now you need to select this datafile and upload the `attributes_Present.Surface.pH.txt` metadata template file so MetaShARK can fill attributes of this file (here the attribute is named "Present.Surface.pH").
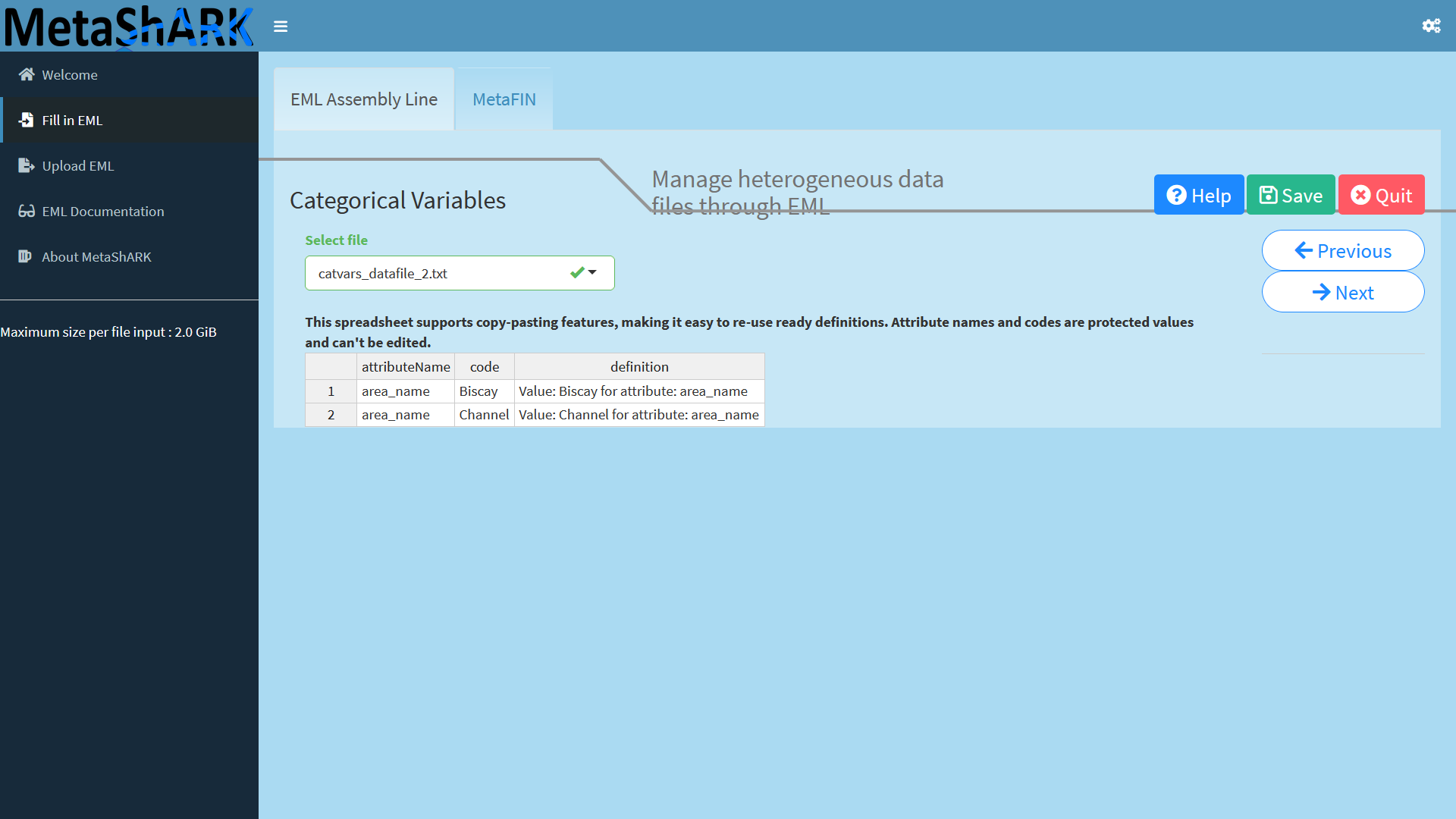
Then you can provide a description for this attribute, for example "Present surface pH", then look at each attribute information of each data file so you can click on the "Next" button and go to the next step, to give informations on categorical variables!
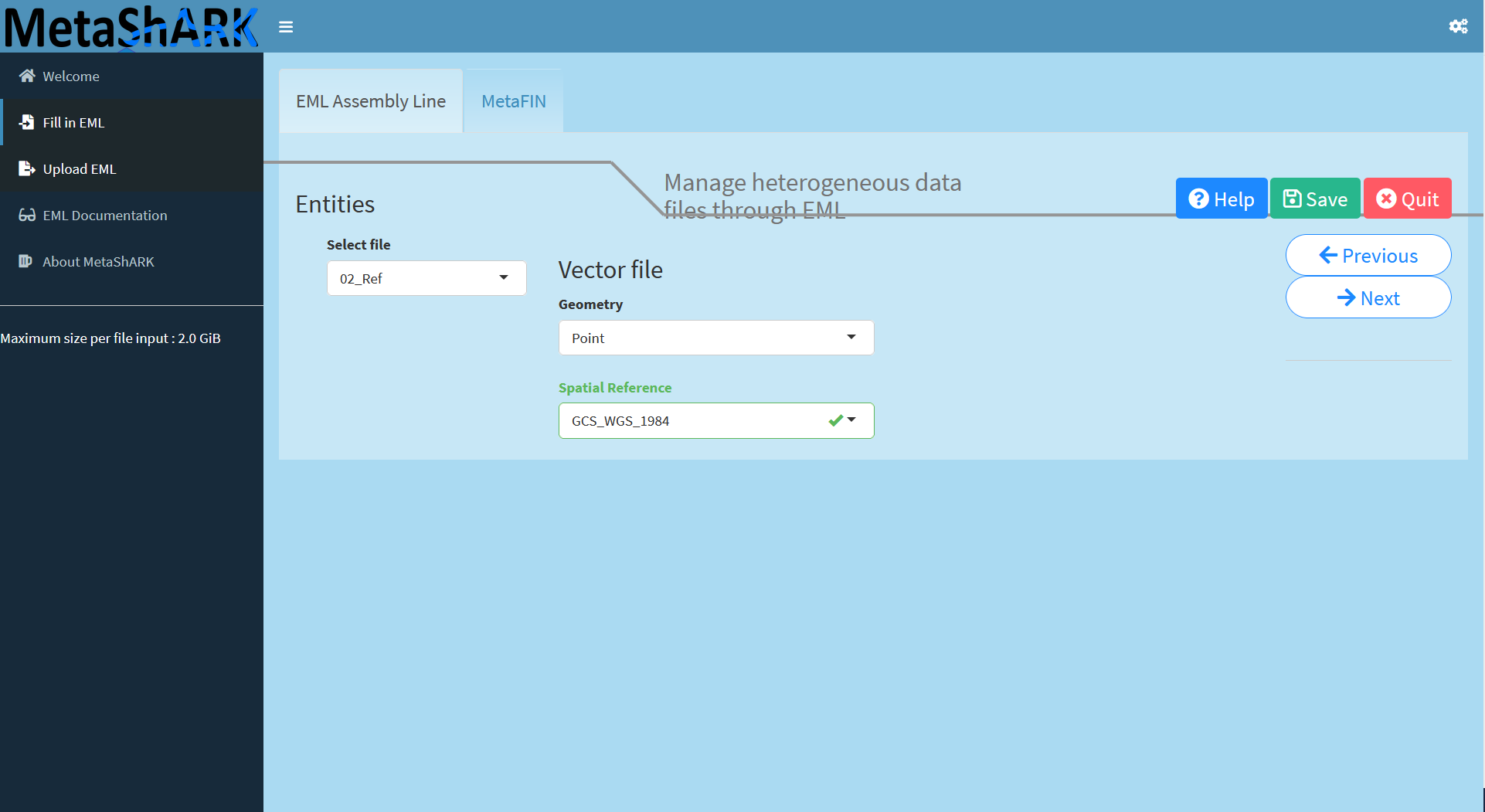
Clicking "Next" button will then allows you to fill spatial informations about all GIS recognized datafiles, here the `Present.Surface.pH.tif` geotiff raster file and the `02_Ref` shapefile vector file. Geotiff is in pixel, accuracy can be set to unknown and shapefile is in Point, both are in `GCS_WGS_1984`spatial reference.
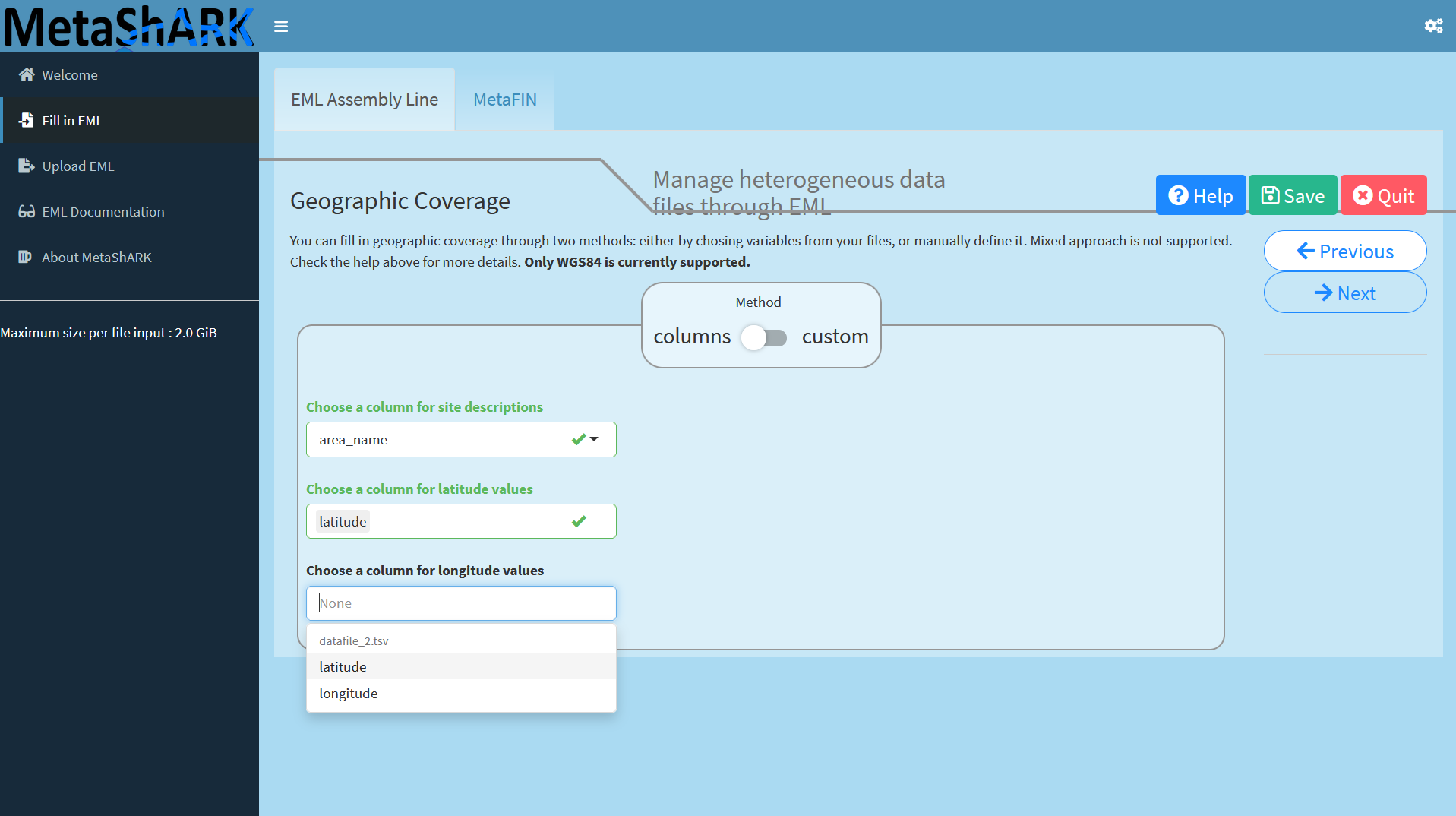
Next step is devoted to specifying geographic coverage.
You can use a method between "columns" or "custom". "Custom" allows you to create one to several geographical sites using a map widget where you can draw limits of each site or enter directly latitude and longitude coordinates. "Columns" method, used here, allows you to specify an attribute containing site names then associated latitude and longitudes attributes.
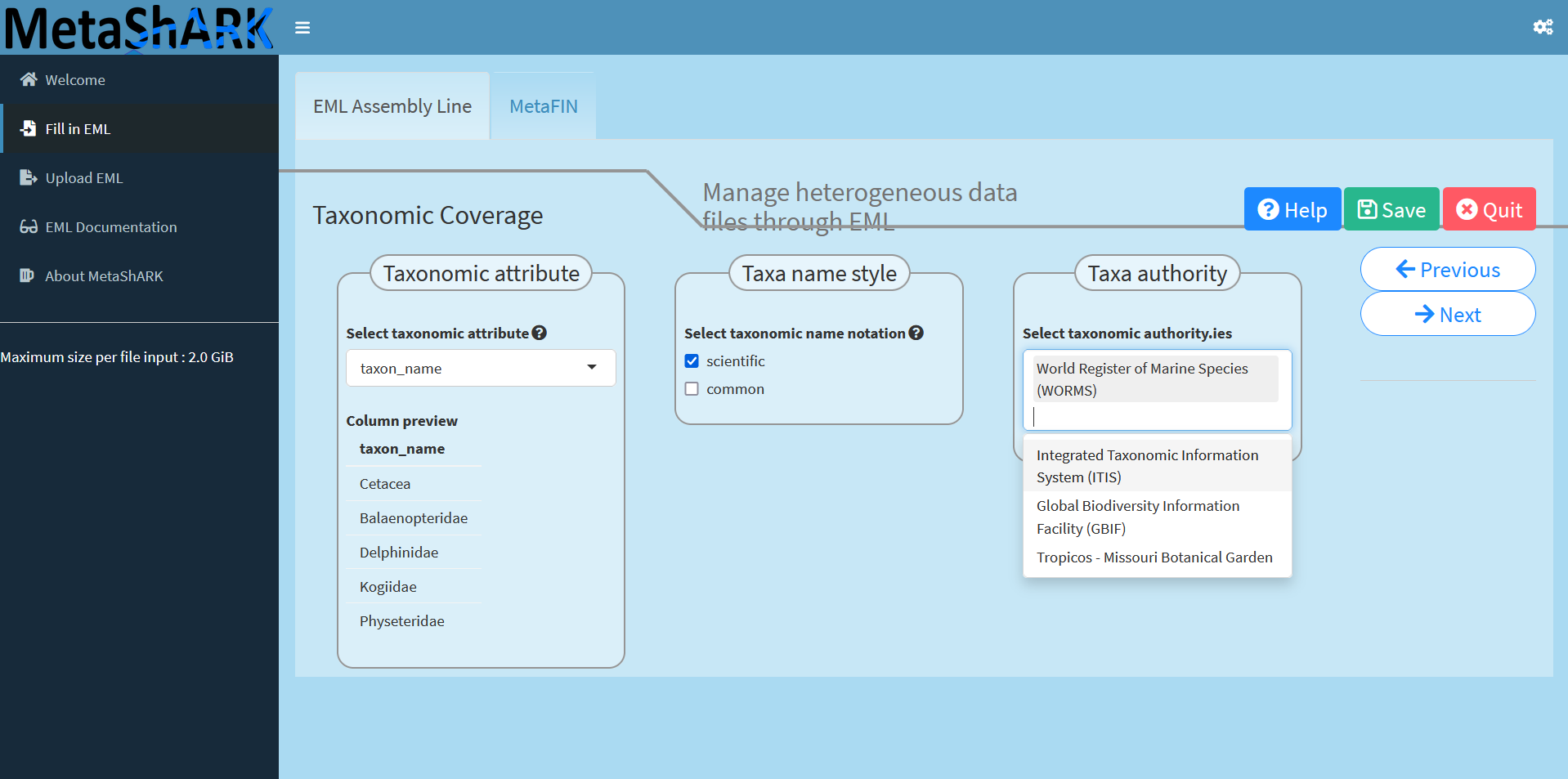
Now geographic coverage is set, one can specific taxonomic coverage.
To do so, you can select a data attribute containing taxonomic information then select kind of notation you want to have and finally on which taxonomic authority (or authorities) information will be compared. Note that this can take a while if you have a lot of taxons and time is duplicated for each selected additional authority.
Now we can fill personal informations.
To do so, the easiest way is to provide ORCID identifiers for each individual person involved as creator, contact and/or PI. Depending on the information filled in ORCID by each individual and on the level of accessibility of each, all field can be automatically filled. If "PI" is selected, you can specify a project name, funder name and related funding number.
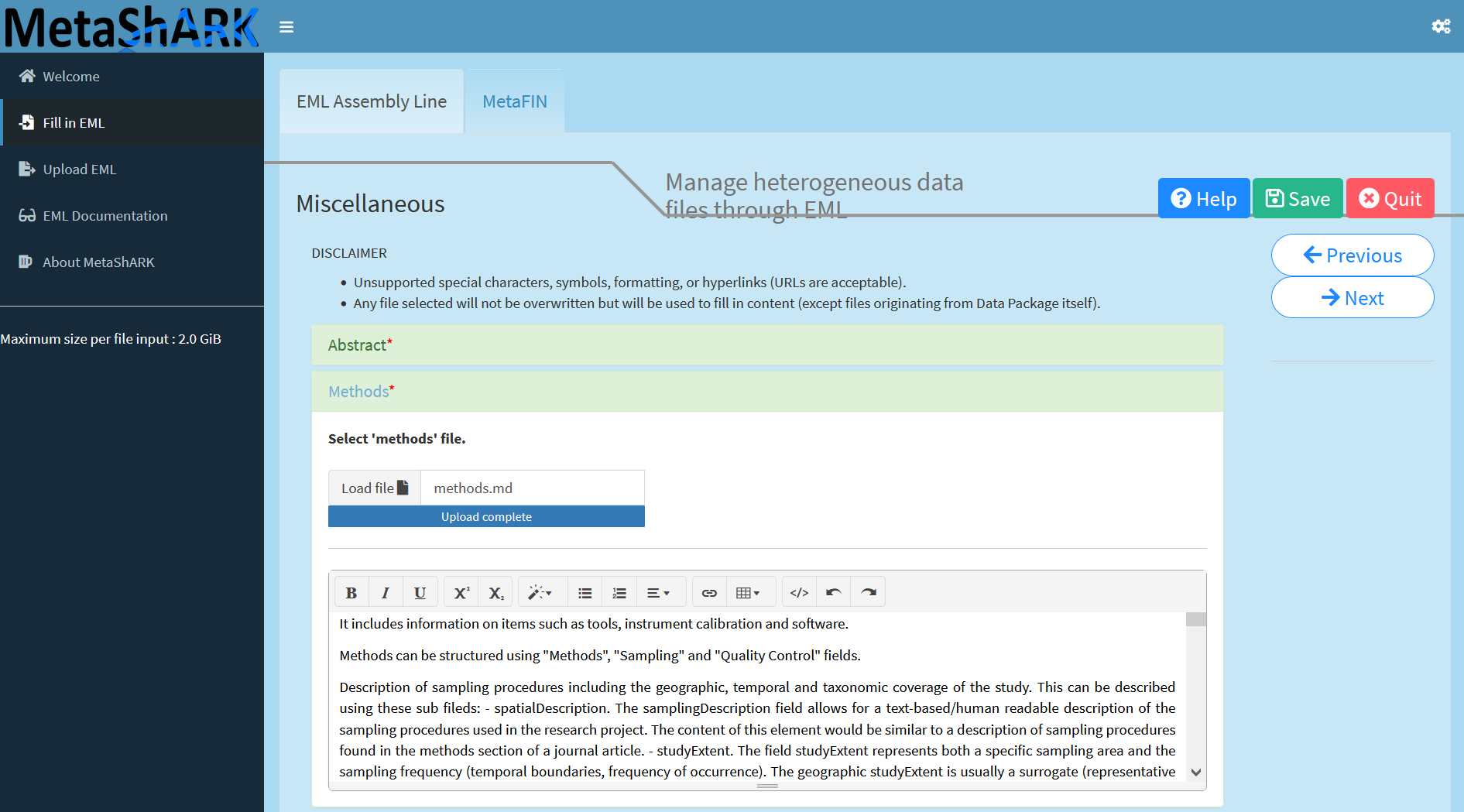
Then you can add final elements as:
An abstract (writing directly on the dedicated field or uploading a text file containing the abstract)
Methods (writing directly on the dedicated field or uploading a text file, can be in markdown, containing details of the methods used to create data files)
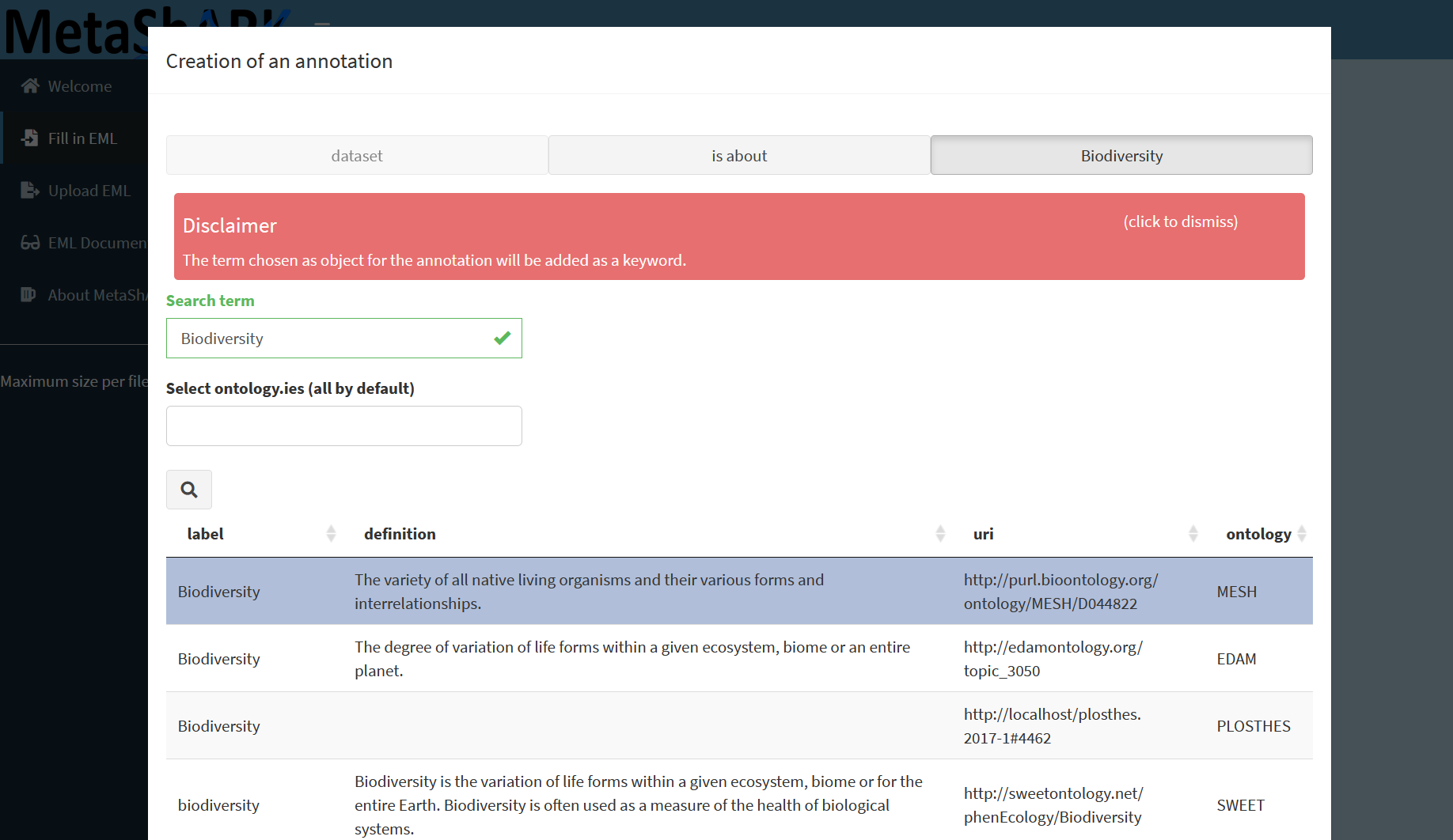
Keywords, who can be linked to keyword thesaurus. This allows you to create “group” of keywords and/or refer to existing terms classifications as we can find in terminological resources such as ontologies or thesaurus.
To do so, you need to reach the MetaShARK parameters (upper right icon) then enter your CEDAR token. To create a CEDAR account, you can 1/ register here http://cedar.metadatacenter.org/ then 2/ go on the "profile" on https://cedar.metadatacenter.org/ and there 3/ you can find the API key.
You then can use the `+` button on the keyword space to **Add keyword with dataset annotation**. You will have to choose a "predicate", from IAO ontology, then an "object" from ontologies coming from Bioportal to add information concerning a "subject", the ‘thing’ being annotated, here, regarding keyword, "dataset", but you can also apply the same to datafiles "attributes".
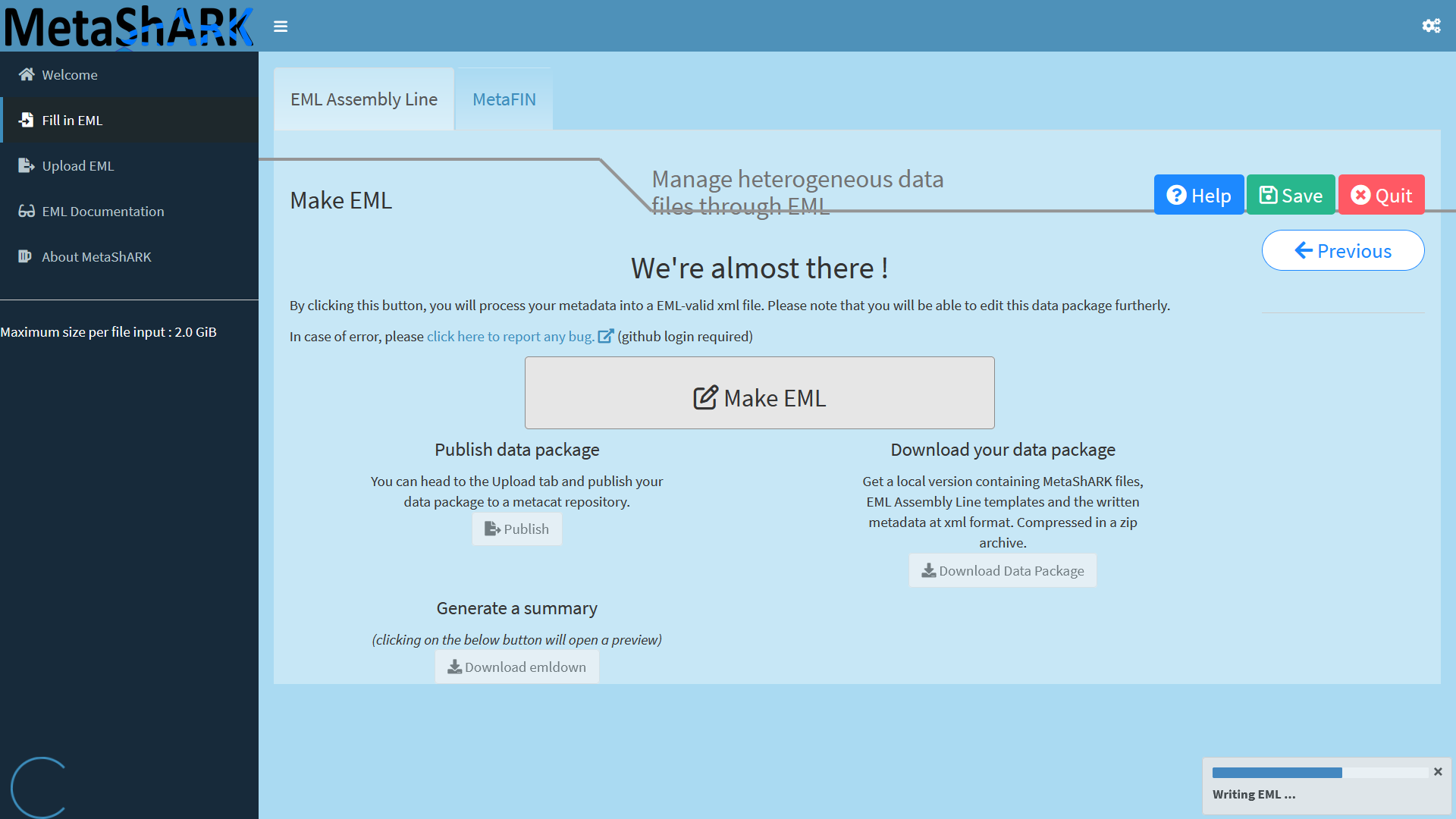
Finally, you can specify a temporal coverage and go to the last step of this MetaShARK workflow: Generat an EML metadata file! If everything is ok, you will have creation of an EML metadata file.
Once EML written, you can download the data package through the button "Download Data Package". This will allow you to download a zip archive you can unzip on your local computer. Resulting files are organized through 2 main folders :
A main folder with data_objects
all datafiles you uploaded into MetaShARK
eml which is the EML metadata file written in XML format
metadata_templates with all metadata files written in text format, column separated by tabulations
A second folder called “emldown” where a draft of data paper written in html format can be accessed
👏 Congratulations! You've just produced your first EML yourself!👏
Warning: MetaShARK can Freeze
At this final stage, MetaShARK can freeze and show like a “front grey filter”
If this is the case, you can refresh MetaShARK app pressing F5 button of your keyboard for example. To dowload the resutling data package, you can go to the “Fill In” module, select the data package you created and click on “Download.zip”.
If you close MetaShARK navigator window, you can reopen it clicking on Menu > User > Active InteractiveTools.
You can here click on “metashark visualization” hyperlink. You can then go on the Fill In module, select
the data package you created and click Load.
4] MetaShRIMPS 🦐 : Easily FAIRness assessment and data paper sketches creation
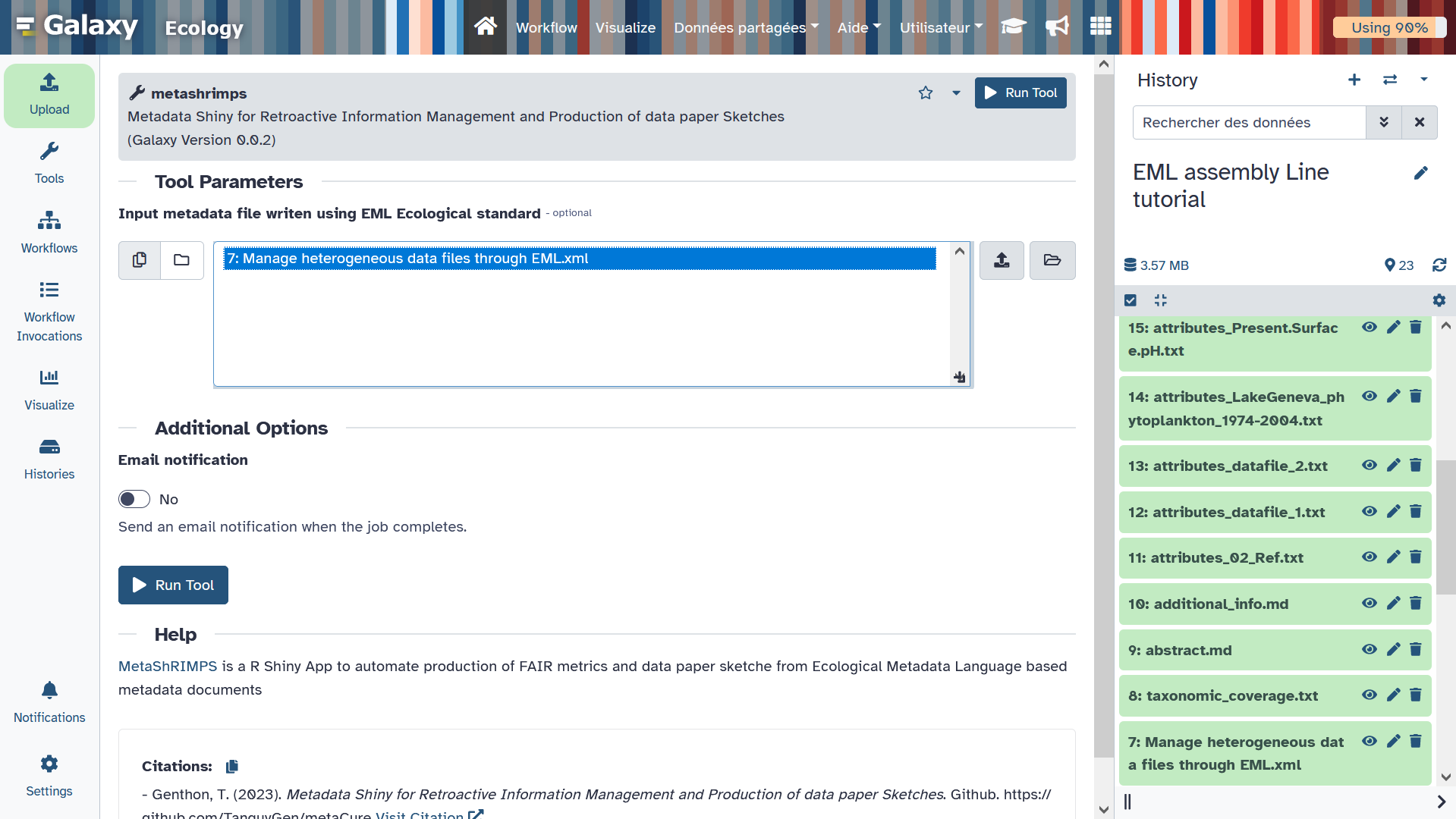
To evaluate and modify metadata elements you have created, you can upload the EML xml file on the Galaxy history you created and all MetaShARK metadata templates files.
Open the MetaShRIMPS interactive tool form and select the EML xml file you just generate with MetaShARK. Clicking on Execute will launch the MetaShRIMPS R Shiny app, the message There is an InteractiveTool result view available, waiting for view to become active... is displayed until the app will be ready to use. After some time, the message There is an InteractiveTool result view available confirm the app is deployed and you can access it clicking on Open. You will then have an interface looking like this:
Click on the Execute Button, 2 new tabs called “Draft of Data Paper” and “Fair Assessment” will appear.
You can access all of the tool outputs by clicking on each tab (it can take a little time for your results to be displayed).
5] Draft of Data Paper 📝
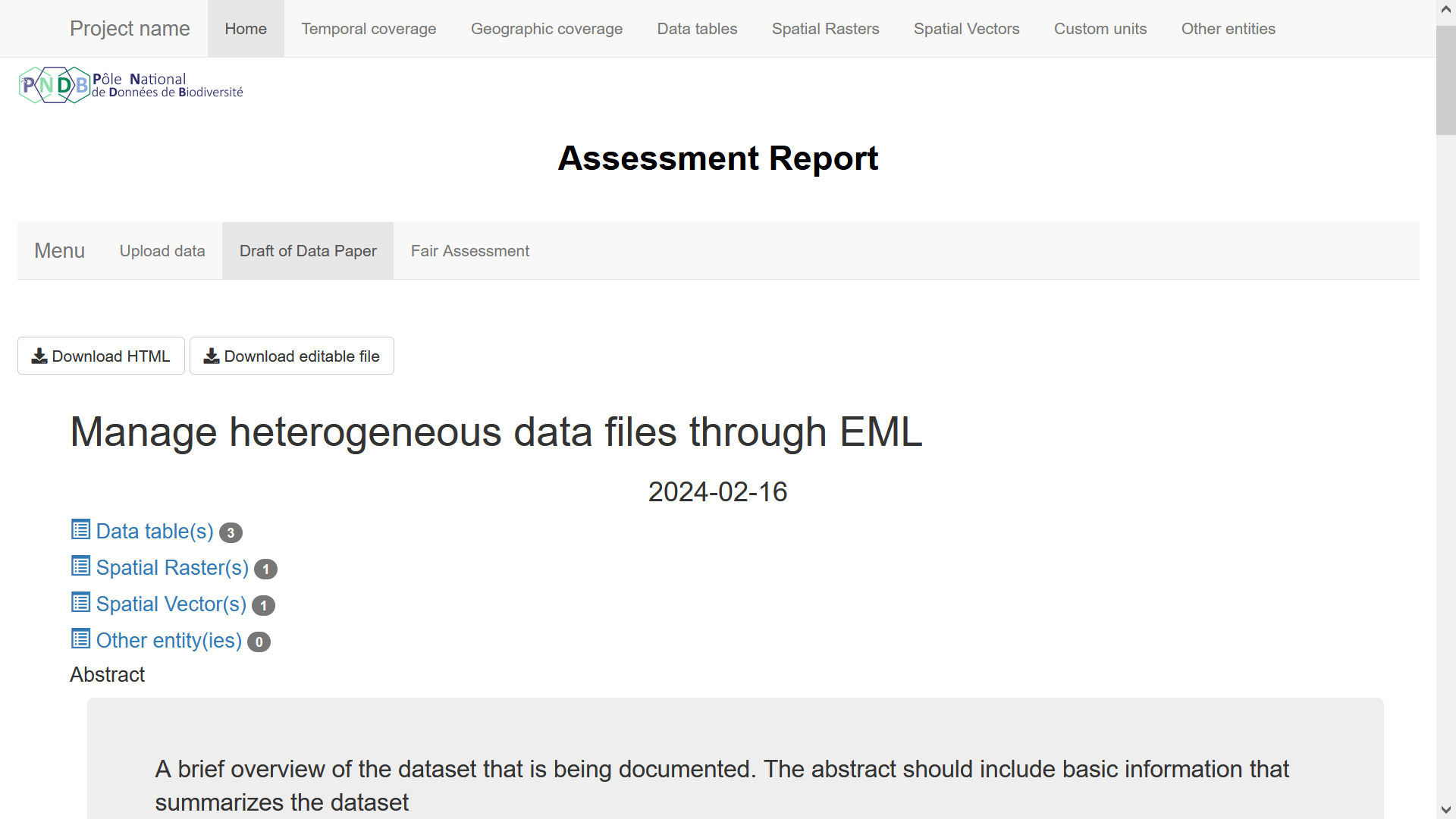
By clicking on the "Draft of Data Paper" tab, you will have access to the draft of Data Paper presented in an HTML format. You can either navigate through the Data Paper with the tabs or with the scrollbar on the right and access different elements.
You can at the top of the page download the draft in either an HTML format …. :
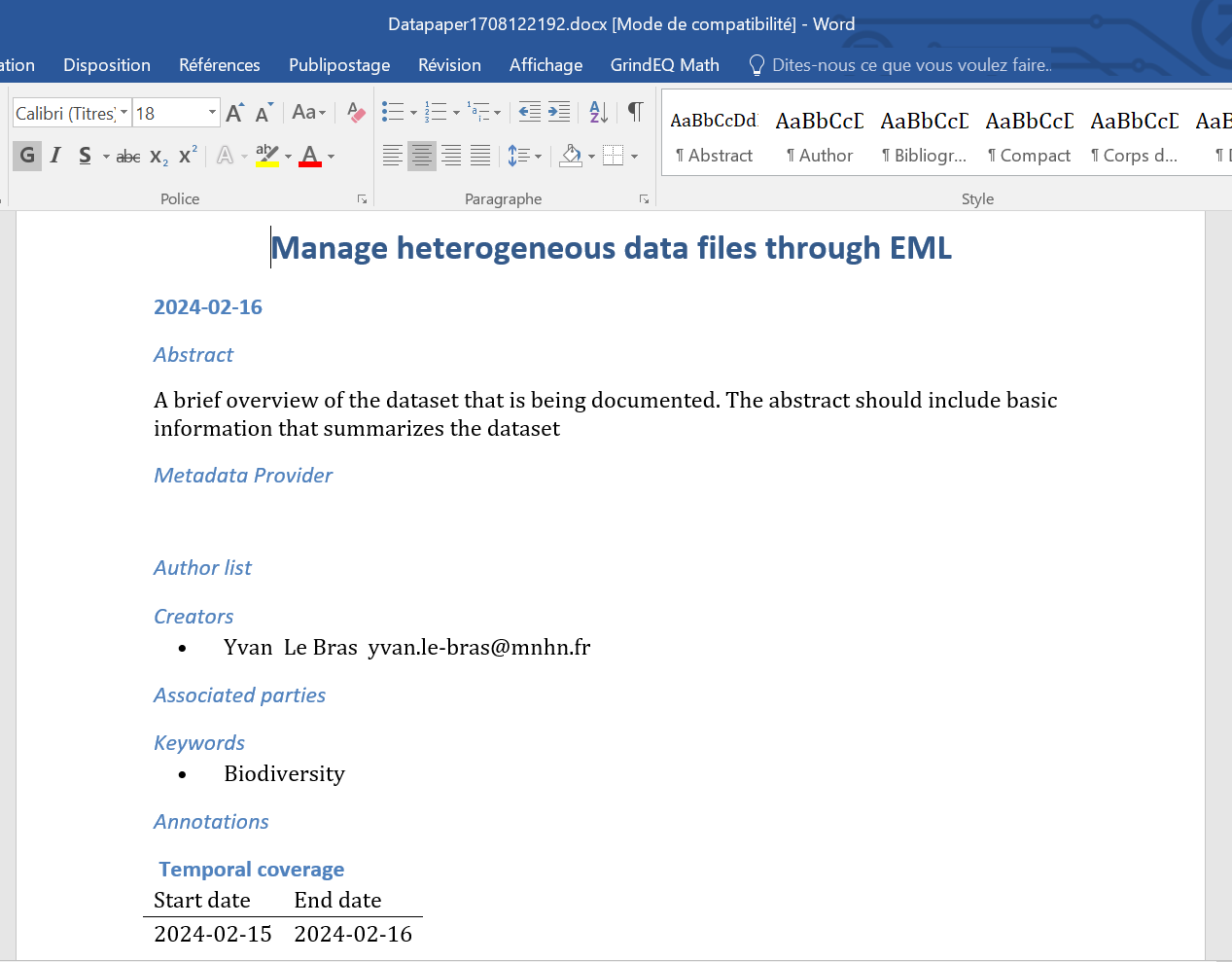
…. or an editable docx format :
Voir comment mettre les deux photos côtés à côtes ou un truc mieux
6] FAIR Quality Assessment report 📊✅
FAIR stand for Findable, Accessible, Interoperable, Reusable.
These principles were to improve the access and usabiliy of data by the machine and to help making data reusable and shareable for users. It covers the whole concept of why it is necessary to produce a rich and described metadata in order to permit external users to understand and reuse data for their own studies.
There are several ways of computing the FAIR index, for each letter of the word is associated with a degree of FAIRitude of the data.
Comment: Metadata Quality
The aim is to propose a metadata quality index and to see how it is possible to improve, not to punish the user 👍
By clicking on the Fair Assessment tab, you will access the FAIR Quality report of the metadata uploaded.
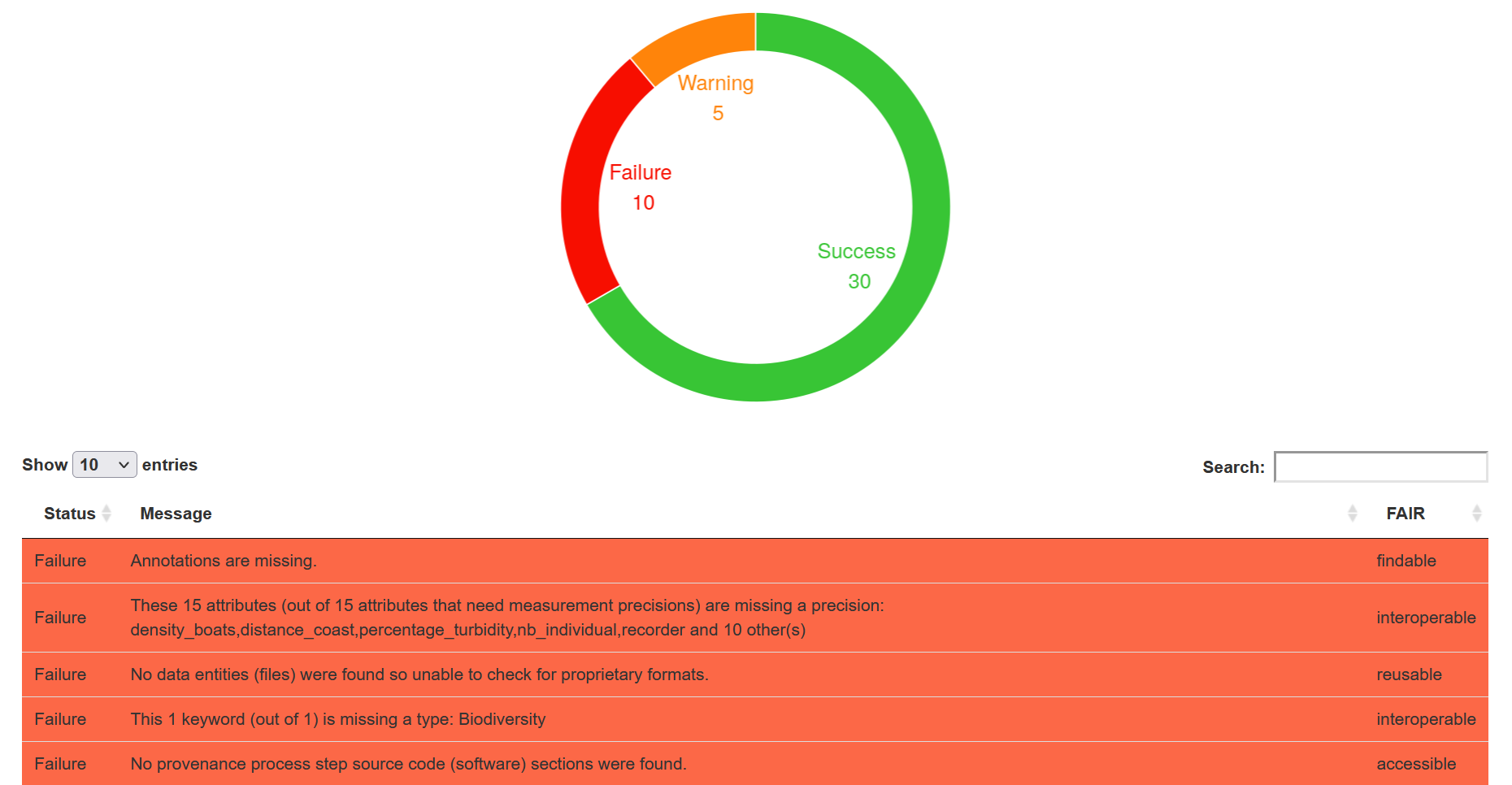
You will have access to different figures such as a table displaying the results of all checks tested for your metadata:
Figure 1: Example of the table displaying the results of the Quality Checks
You will also have acces to a graph presenting scores of Quality for each of the FAIR principles tested (Findable,
Acessible, Interoperable, Reusable) on a 100 point scale.
Image un peu laide, je l’a modifierai un peu sur Paint pour optimiser sa taille vis à vis du vide/blanc occupé par certaines parties
Comment: How you can improve your FAIR score?
You can look at the lines of the table for FAILURE (red) and WARNING (yellow) status. Two WARNING
status lines are related to an abstract content too short and an attribute definition too small.
Comment: Update metadata content to elevate FAIR score
Search “abstract” and “attributes_Present.Surface.pH.txt” metadarta files on your history
Modify each file using the Galaxy included text editor
To do so, you can go on the “visualize” functionnality of each datafile, clicking on the name of the dataset on your history then on the “visualize” button at the bottom of the dataset description. you can then select “Editor / Manually edit text” to update the content and generate a new version of the dataset.
Rename each datafile as original names (“abstract” and “attributes_Present.Surface.pH.txt”), you can add a “modified” tag / label so you can better remember in the future the modification state.
Recreate a data collection with all metadata template files, taking the new “abstract” and “attributes_Present.Surface.pH.txt” files instead of old ones.
You can recreate an EML metadata file with Make EML EAL tool and then redeploy a metashrimps tool on the new EML. Before executing Make EML EAL tool, one need to pay attention to the rename composite datafiles (as here the shapefile one) as named originally (so 02_Ref) and then create a data collection gathering all “dataTable” datafiles (both .tsv files and .nc one), a data collection gathering all “spatialRaster” datafiles (here Present.Surface.pH.tif) and a data collection gathering all “spatialVector” datafiles (here LakeGeneva_phytoplankton_1974-2004.nc).
7] Conclusion
Here is the end of this short tutorial aiming in explaining the purpose of MetaShARK and how to use it.
Don’t hesitate to contact us if you have any questions ☺️
You've Finished the Tutorial
Please also consider filling out the Feedback Form as well!
Key points
This tool aims to improve FAIR quality of metadata focusing on user exeprience and automatic inferences
Creating metadata as FAIR as possible is a must
Be carefull of the format and standard of metadata used only EML metadata will work
Frequently Asked Questions
Have questions about this tutorial? Have a look at the available FAQ pages and support channels
Further information, including links to documentation and original publications, regarding the tools, analysis techniques and the interpretation of results described in this tutorial can be found here.
Feedback
Did you use this material as an instructor? Feel free to give us feedback on how it went.
Did you use this material as a learner or student? Click the form below to leave feedback.
Hiltemann, Saskia, Rasche, Helena et al., 2023 Galaxy Training: A Powerful Framework for Teaching! PLOS Computational Biology 10.1371/journal.pcbi.1010752
Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
@misc{ecology-MetaShARK_tutorial,
author = "Yvan Le Bras and Glinez Thibaud",
title = "Creating metadata using Ecological Metadata Language (EML) standard with EML Assembly Line functionalities (Galaxy Training Materials)",
year = "",
month = "",
day = "",
url = "\url{https://training.galaxyproject.org/training-material/topics/ecology/tutorials/MetaShARK_tutorial/tutorial.html}",
note = "[Online; accessed TODAY]"
}
@article{Hiltemann_2023,
doi = {10.1371/journal.pcbi.1010752},
url = {https://doi.org/10.1371%2Fjournal.pcbi.1010752},
year = 2023,
month = {jan},
publisher = {Public Library of Science ({PLoS})},
volume = {19},
number = {1},
pages = {e1010752},
author = {Saskia Hiltemann and Helena Rasche and Simon Gladman and Hans-Rudolf Hotz and Delphine Larivi{\`{e}}re and Daniel Blankenberg and Pratik D. Jagtap and Thomas Wollmann and Anthony Bretaudeau and Nadia Gou{\'{e}} and Timothy J. Griffin and Coline Royaux and Yvan Le Bras and Subina Mehta and Anna Syme and Frederik Coppens and Bert Droesbeke and Nicola Soranzo and Wendi Bacon and Fotis Psomopoulos and Crist{\'{o}}bal Gallardo-Alba and John Davis and Melanie Christine Föll and Matthias Fahrner and Maria A. Doyle and Beatriz Serrano-Solano and Anne Claire Fouilloux and Peter van Heusden and Wolfgang Maier and Dave Clements and Florian Heyl and Björn Grüning and B{\'{e}}r{\'{e}}nice Batut and},
editor = {Francis Ouellette},
title = {Galaxy Training: A powerful framework for teaching!},
journal = {PLoS Comput Biol}
}
Funding
These individuals or organisations provided funding support for the development of this resource
Questions:






 Open image in new tab
Open image in new tab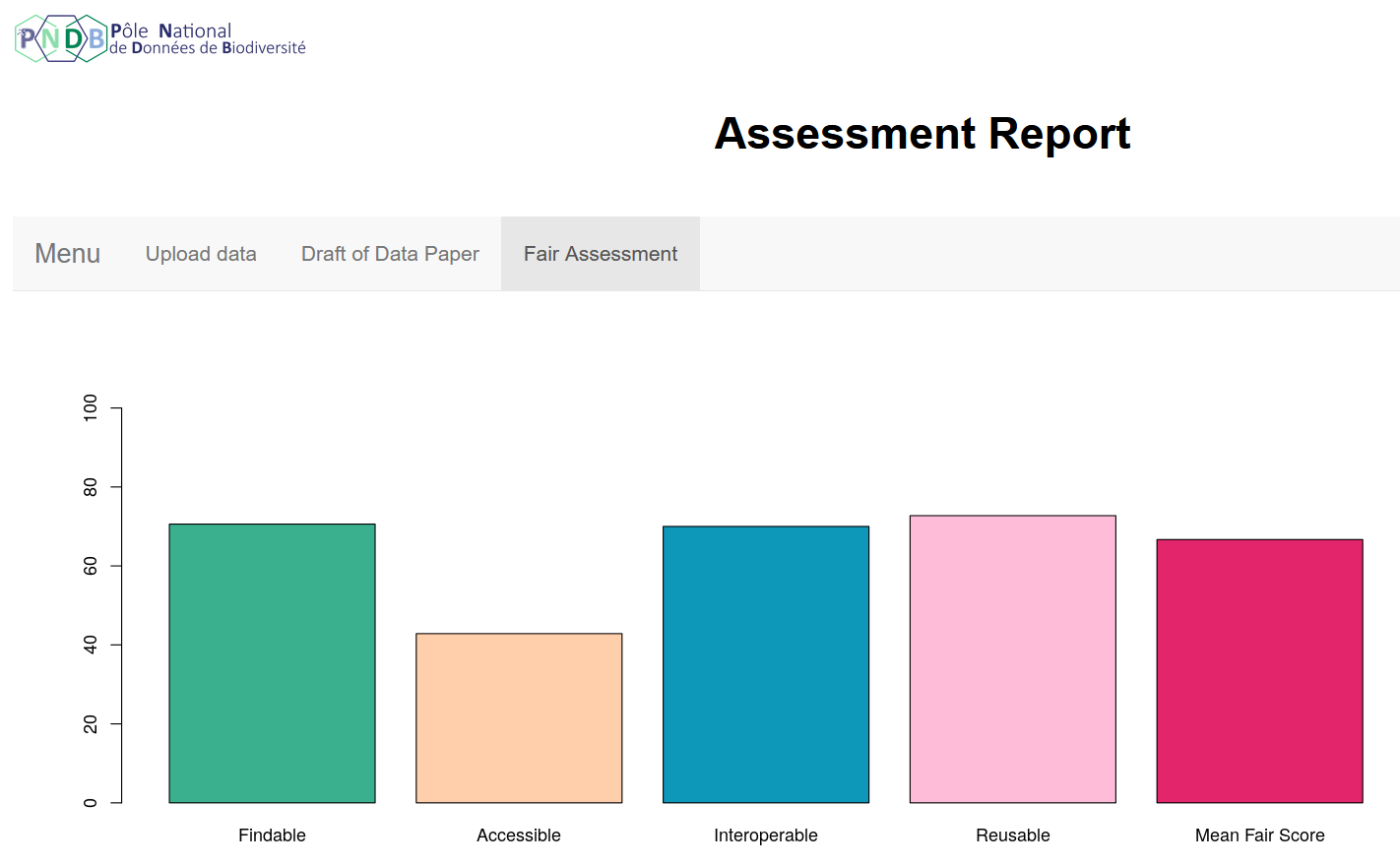 Open image in new tab
Open image in new tabOpen image in new tab


