Introduction to sequencing with Python (part one)
Under Development!
This tutorial is not in its final state. The content may change a lot in the next months. Because of this status, it is also not listed in the topic pages.
| Author(s) |
|
| Reviewers |
|
OverviewQuestions:
Objectives:
What are the origins of Sanger sequencing
How did sequencing machines evolve?
How can we simulate Sanger sequencing with Python?
Have a basic understanding of the history of sequencing
Understand Python basics
Time estimation: 1 hourSupporting Materials:Published: Jan 23, 2024Last modification: Feb 20, 2024License: Tutorial Content is licensed under Creative Commons Attribution 4.0 International License. The GTN Framework is licensed under MITpurl PURL: https://gxy.io/GTN:T00397rating Rating: 5.0 (0 recent ratings, 1 all time)version Revision: 2
Best viewed in a Jupyter NotebookThis tutorial is best viewed in a Jupyter notebook! You can load this notebook one of the following ways
Run on the GTN with JupyterLite (in-browser computations)
Launching the notebook in Jupyter in Galaxy
- Instructions to Launch JupyterLab
- Open a Terminal in JupyterLab with File -> New -> Terminal
- Run
wget https://training.galaxyproject.org/training-material/topics/data-science/tutorials/gnmx-lecture2/data-science-gnmx-lecture2.ipynb- Select the notebook that appears in the list of files on the left.
Downloading the notebook
- Right click one of these links: Jupyter Notebook (With Solutions), Jupyter Notebook (Without Solutions)
- Save Link As..

The problem
The difficulty with sequencing nucleic acids is nicely summarized by Hutchinson 2007:
- The chemical properties of different DNA molecules were so similar that it appeared difficult to separate them.
- The chain length of naturally occurring DNA molecules was much greater than for proteins and made complete sequencing seem unapproachable.
- The 20 amino acid residues found in proteins have widely varying properties that had proven useful in the separation of peptides. The existence of only four bases in DNA therefore seemed to make sequencing a more difficult problem for DNA than for protein.
- No base-specific DNAases were known. Protein sequencing had depended upon proteases that cleave adjacent to certain amino acids.
It is therefore not surprising that protein-sequencing was developed before DNA sequencing by Sanger and Tuppy 1951.
tRNA was the first complete nucleic acid sequenced (see pioneering work of Robert Holley and colleagues and also Holley’s Nobel Lecture). Conceptually, Holley’s approach was similar to Sanger’s protein sequencing: break molecule into small pieces with RNases, determine sequences of small fragments, and use overlaps between fragments to reconstruct (assemble) the final nucleotide sequence.
The work on finding approaches to sequencing DNA molecules began in the late 60s and early 70s. One of the earliest contributions has been made by Ray Wu (Cornell) and Dave Kaiser (Stanford), who used E. coli DNA polymerase to incorporate radioactively labelled nucleotides into protruding ends of bacteriphage lambda. It took several more years for the development of more “high throughput” technologies by Sanger and Maxam/Gilbert. The Sanger technique has ultimately won over Maxam/Gilbert’s protocol due to its relative simplicity (once dideoxynucleotides has become commercially available) and the fact that it required a smaller amount of starting material as the polymerase was used to generate fragments necessary for sequence determination.
Sanger/Coulson plus/minus method
Comment: Two Nobel prizesFred Sanger is one of only four people, who received two Nobel Prizes in their original form (for scientific, not societal, breakthroughs).
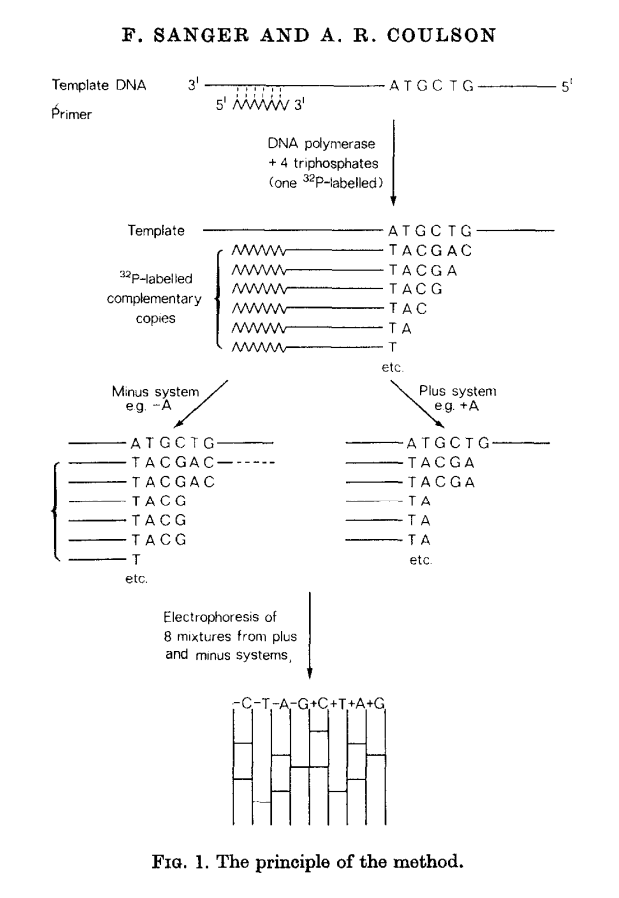
This method builds on the idea of Wu and Kaiser (for minus part) and on the special property of DNA polymerase isolated from phage T4 (for plus part). The schematics of the method is given in the following figure (from Sanger & Coulson: 1975):
 Open image in new tab
Open image in new tabIn this method, a primer and DNA polymerase is used to synthesize DNA in the presence of P32-labeled nucleotides (only one of four is labeled). This generates P32-labeled copies of DNA being sequenced. These are then purified and (without denaturing) separated into two groups: minus and plus. Each group is further divided into four equal parts.
In the case of minus polymerase a mix of nucleotides minus one is added to each of the four aliquotes: ACG (-T), ACT (-G), CGT (-A), AGT (-C). As a result in each case DNA strand is extended up to a missing nucleotide.
In the case of plus only one nucleotide is added to each of the four aliquotes (+A, +C, +G, and +T) and T4 DNA polymerase is used. T4 DNA polymerase acts as an exonuclease that would degrade DNA from 3’-end up to a nucleotide that is supplied in the reaction.
The products of these are loaded into a denaturing polyacrylamide gel as eight tracks (four for minus and four for plus; from Sanger & Coulson: 1975):
 Open image in new tab
Open image in new tabMaxam/Gilbert chemical cleavage method
In this method DNA is terminally labeled with P32, separated into four equal aliquotes. Two of these are treated with Dimethyl sulfate (DMSO) and the remaining two are treated with hydrazine.
DMSO methylates G and A residues. Treatment of DMSO-incubated DNA with alkali at high temperature will break DNA chains at G and A with Gs being preferentially broken, while treatment of DMSO-incubated DNA with acid will preferentially break DNA at As. Likewise treating hydrazine-incubated DNA with piperidine breaks DNA at C and T, while DNA treated with hydrazine in the presence of NaCl preferentially breaks at Cs. The four reactions are then loaded on a gel generating the following picture (from Maxam & Gilbert: 1977):
 Open image in new tab
Open image in new tabSanger dideoxy method
The original Sanger +/- method was not popular and had a number of technical limitations. In a new approach, Sanger took advantage of inhibitors that stop the extension of a DNA strand at particular nucleotides. These inhibitors are dideoxy analogs of normal nucleotide triphosphates (from Sanger et al. 1977):
 Open image in new tab
Open image in new tabOriginal approaches were laborious
In the original Sanger paper the authors sequenced bacteriophage phiX174 by using its own restriction fragments as primers. This was an ideal set up to show the proof of principle for the new method. This is because phiX174 DNA is homogeneous and can be isolated in large quantities. Now suppose that you would like to sequence a larger genome (say E. coli). Remember that the original version of Sanger method can only sequence fragments up to 200 nucleotides at a time. So to sequence the entire E. coli genome (which by-the-way was not sequenced until 1997) you would need to split the genome into multiple pieces and sequence each of them individually. This is hard because to produce a readable Sanger sequencing gel each sequence must be amplified to a suitable amount (around 1 nanogram) and be homogeneous (you cannot mix multiple DNA fragments in a single reaction as it will be impossible to interpret the gel). Molecular cloning enabled by the availability of commercially available restriction enzymes and cloning vectors simplified this process. Until the onset of next generation sequencing in 2005 the process for sequencing looked something like this:
- (1) - Generate a collection of fragments you want to sequence. It can be a collection of fragments from a genome that was mechanically sheared or just a single fragment generated by PCR.
- (2) - These fragment(s) are then cloned into a plasmid vector (we will talk about other types of vectors such as BACs later in the course).
- (3) - Vectors are transformed into bacterial cells and positive colonies (containing vectors with insert) are picked from an agar plate.
- (4) - Each colony now represents a unique piece of DNA.
- (5) - An individual colony is used to seed a bacterial culture that is grown overnight.
- (6) - Plasmid DNA is isolated from this culture and now can be used for sequencing because it is (1) homogeneous and (2) we now have a sufficient amount.
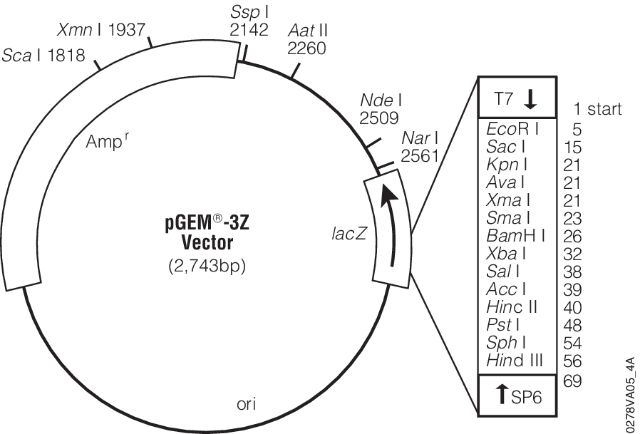
- (7) - It is sequenced using universal primers. For example, the image below shows a map for pGEM-3Z plasmid (a pUC18 derivative). Its multiple cloning site is enlarged and sites for T7 and SP6 sequencing primers are shown.
- These are the pads I’m referring to in the lecture. These provide universal sites that can be used to sequence any insert in between.
 Open image in new tab
Open image in new tabUntil the invention of NGS the above protocol was followed with some degree of automation. But you can see that it was quite laborious if the large number of fragments needed to be sequenced. This is because each of them needed to be subcloned and handled separately. This is in part why the Human Genome Project, which will be discussed in future lectures in detail, took so much time to complete.
Evolution of sequencing machines
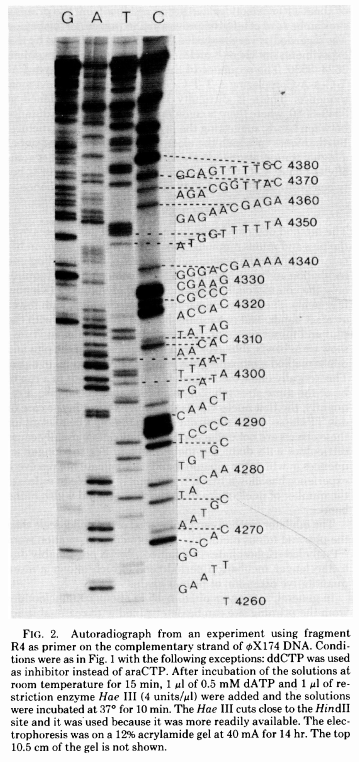
The simplest possible sequencing machine is a gel rig with polyacrylamide gel. Sanger used it is his protocol obtaining the following results (from Sanger et al. 1977):
 Open image in new tab
Open image in new tabHere for sequencing each fragment four separate reactions are performed (with ddA, ddT, ggC, and ddG) and four lanes on the gel are used. One simplification of this process that came in the 90s was to use fluorescently labeled dideoxy nucleotides. This is easier because everything can be performed in a single tube and uses a single lane on a gel (from Applied Biosystems support site):
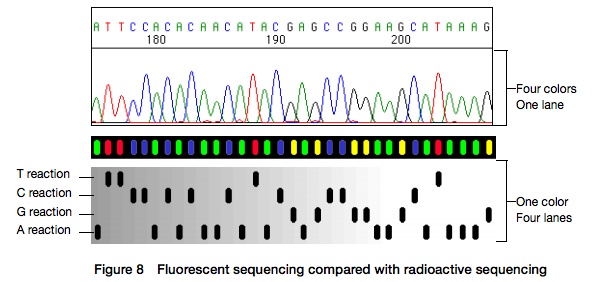 Open image in new tab
Open image in new tabHowever, there is still substantial labor involved in pouring the gels, loading them, running machines, and cleaning everything post-run. A significant improvement was offered by the development of capillary electrophoresis allowing automation of liquid handling and sample loading. Although several manufacturers have been developing and selling such machines a de facto standard in this area was (and still is) the Applied Biosystems (ABI) Genetics and DNA Analyzer systems. The highest throughput ABI system, 3730xl, had 96 capillaries and could automatically process 384 samples.
NGS!
384 samples may sound like a lot, but it is nothing if we are sequencing an entire genome. The beauty of NGS is that these technologies are not bound by sample handling logistics. They still require the preparation of libraries, but once a library is made (which can be automated) it is processed more or less automatically to generate multiple copies of each fragment (in the case of 454, Illumina, Ion Torrent, PacBio, Oxford Nanopore, Element, Complete Genomics etc…) and loaded onto the machine, where millions of individual fragments are sequenced simultaneously. We will learn about these technologies later in this course.
Reading
- 2001 Overview of pyrosequencing methodology - Ronaghi
- 2005 Description of 454 process - Margulies et al.
- 2007 History of pyrosequencing - Pål Nyrén
- 2007 Errors in 454 data - Huse et al.
- 2010 Properties of 454 data - Balzer et al.
A few classical papers
In a series of now classical papers (Paper 1, Paper2) Philip Green and co-workers have developed a quantitative framework for the analysis of data generated by automated DNA sequencers:
 Open image in new tab
Open image in new tab Open image in new tab
Open image in new tabIn particular, they developed a standard metric for describing the reliability of base calls:
An important technical aspect of our work is the use of log-transformed error probabilities rather than untransformed ones, which facilitates working with error rates in the range of most importance (very close to 0). Specifically, we define the quality value \(q\) assigned to a base-call to be:
\[q = -10\times log\_{10}(p)\]where \(p\) is the estimated error probability for that base-call. Thus a base-call having a probability of 1/1000 of being incorrect is assigned a quality value of 30. Note that high-quality values correspond to low error probabilities, and conversely.
We will be using the concept of “quality score” or “phred-scaled quality score” repeatedly in this course.
Myers - Green debate
Can we sequence a genome using the shotgun approach?
 Open image in new tab
Open image in new tabSimulating Sanger sequencing with Python
In this lesson we will cover some of the fundamental Python basics including variables, expressions, statements, and functions.
Prep
- Start JupyterLab
- Within JupyterLab start a new Python3 notebook
Preclass prep: Chapters 1, 2, 3 from “Think Python”
Indentation is everything!
Warning: Indentation or bust!Python is an indented language: code blocks are defined using indentation with spaces!
In Python, indentation is used to indicate the scope of control structures such as for loops, if statements, and function and class definitions. The amount of indentation is not fixed, but it must be consistent within a block of code.
The recommended amount of indentation is 4 spaces, although some developers prefer to use 2 spaces. Indenting is important in Python because it is used to indicate the level of nesting and structure of the code,
which makes it easier to read and understand. Additionally, indentation is also used to indicate which lines of code are executed together as a block.
The storyline
In this lecture, we will re-implement our Sanger sequencing simulator from the previous lecture and generate realistic gel images.
Generate a random sequence
First, we import a module called random which contains a number of functions for generating and working with random numbers
import random
Next, we will write a simple loop that would generate a sequence of pre-set lengths:
seq = ''
for _ in range(100):
seq += random.choice('ATCG')
seq
CTTGCGGCTATAGGAATAAAAGGCTTTGCGGGTAGTGACCGCGCCGCGTATGTAATTCATGGGTGTCGTCGCGCCCTCACAACTGCAAGGTCGTGGCACC
Simulate one polymerase molecule
The code below iterates through each element of a sequence seq (assumed to be a string containing nucleotides) and it checks if the current nucleotide is equal to ‘A’. If it is, it generates a random number between 0 and 1 using the random.random() function.
It then checks if the random number is greater than 0.5. If it is, the code does nothing and proceeds to the next iteration. If the random number is less than or equal to 0.5, the code adds the
lowercase version of the nucleotide (‘a’) to a string called synthesized_strand and then breaks out of the loop.
In every iteration of the loop, regardless of whether the nucleotide is ‘A’ or not, the code then adds the current nucleotide to the synthesized_strand string.
This means that when the current nucleotide is ‘A’, then the generated random number will decide whether the code will add the nucleotide ‘A’ or ‘a’ to the synthesized_strand, and it will break out of the loop
after adding the nucleotide to the synthesized_strand. To get a good idea of what is going on let’s visualize the code execution in
synthesized_strand = ''
for nucleotide in seq:
if nucleotide == 'A':
d_or_dd = random.random()
if d_or_dd > 0.5:
None
else:
synthesized_strand += 'a'
break
synthesized_strand += nucleotide
This can be simplified by first removing d_or_dd variable:
synthesized_strand = ''
for nucleotide in seq:
if nucleotide == 'A':
if random.random() > 0.5:
None
else:
synthesized_strand += 'a'
break
synthesized_strand += nucleotide
print(synthesized_strand)
CTTGCGGCTATa
and removing an unnecessary group of if ... else statements:
synthesized_strand = ''
for nucleotide in seq:
if nucleotide == 'A' and random.random() > 0.5:
synthesized_strand += 'a'
break
synthesized_strand += nucleotide
print(synthesized_strand)
CTTGCGGCTATAGGAATa
finally let’s make synthesized_strand += 'a' a bit more generic:
synthesized_strand = ''
for nucleotide in seq:
if nucleotide == 'A' and random.random() > 0.5:
synthesized_strand += nucleotide.lower()
break
synthesized_strand += nucleotide
print(synthesized_strand)
CTTGCGGCTATAGGa
Simulating multiple molecules
To simulate 10 polymerase molecules we simply wrap the code from above into a for loop:
for _ in range(10):
synthesized_strand = ''
for nucleotide in seq:
if nucleotide == 'A' and random.random() > 0.5:
synthesized_strand += nucleotide.lower()
break
synthesized_strand += nucleotide
print(synthesized_strand)
CTTGCGGCTa
CTTGCGGCTa
CTTGCGGCTa
CTTGCGGCTa
CTTGCGGCTa
CTTGCGGCTa
CTTGCGGCTATa
CTTGCGGCTATAGGa
CTTGCGGCTa
CTTGCGGCTa
One problem with this code is that does not actually save the newly synthesized strand: it simply prints it. To fix this we will create a list
(or an array) called new_strands and initialize it by assigning an empty array to it:
new_strands = []
for _ in range(10):
synthesized_strand = ''
for nucleotide in seq:
if nucleotide == 'A' and random.random() > 0.5:
synthesized_strand += nucleotide.lower()
break
synthesized_strand += nucleotide
new_strands.append(synthesized_strand)
new_strands
['CTTGCGGCTa',
'CTTGCGGCTa',
'CTTGCGGCTATAGGAATAa',
'CTTGCGGCTATAGGAATa',
'CTTGCGGCTATa',
'CTTGCGGCTATAGGa',
'CTTGCGGCTATAGGa',
'CTTGCGGCTATa',
'CTTGCGGCTATAGGa',
'CTTGCGGCTa']
Simulating multiple molecules and all nucleotides
And to repeat this for the remaining three nucleotides we will do the following crazy thing:
new_strands = []
for _ in range(10):
synthesized_strand = ''
for nucleotide in seq:
if nucleotide == 'A' and random.random() > 0.5:
synthesized_strand += nucleotide.lower()
break
synthesized_strand += nucleotide
new_strands.append(synthesized_strand)
for _ in range(10):
synthesized_strand = ''
for nucleotide in seq:
if nucleotide == 'C' and random.random() > 0.5:
synthesized_strand += nucleotide.lower()
break
synthesized_strand += nucleotide
new_strands.append(synthesized_strand)
for _ in range(10):
synthesized_strand = ''
for nucleotide in seq:
if nucleotide == 'G' and random.random() > 0.5:
synthesized_strand += nucleotide.lower()
break
synthesized_strand += nucleotide
new_strands.append(synthesized_strand)
for _ in range(10):
synthesized_strand = ''
for nucleotide in seq:
if nucleotide == 'T' and random.random() > 0.5:
synthesized_strand += nucleotide.lower()
break
synthesized_strand += nucleotide
new_strands.append(synthesized_strand)
len(new_strands)
40
Repeating the same code four times is just plain stupid so instead we will write a function called polymerase. Here we need to worry about the scope of variables. The scope of a variable refers to the regions
of the code where the variable can be accessed or modified. Variables that are defined within a certain block of code (such as a function or a loop) are said to have a local scope, meaning that they can
only be accessed within that block of code. Variables that are defined outside of any block of code are said to have a global scope, meaning that they can be accessed from anywhere in the code.
In most programming languages, a variable defined within a function has a local scope, and it can only be accessed within that function. If a variable with the same name is defined outside the function, it will have a global scope and can be accessed from anywhere in the code. However, if a variable with the same name is defined within the function, it will take precedence over the global variable and will be used within the function.
There are also some languages that have block scope, where a variable defined within a block (such as an if statement or a for loop) can only be accessed within that block and not outside of it.
In Python, variables defined in the main module have a global scope and can be accessed from any function or module. Variables defined within a function have local scope, and they can only be accessed within that function. Variables defined within a loop or a block can be accessed only within the scope of the loop or block.
def ddN(number_of_iterations, template, base, ddN_ratio):
new_strands = []
for _ in range(number_of_iterations):
synthesized_strand = ''
for nucleotide in template:
if nucleotide == base and random.random() > ddN_ratio:
synthesized_strand += nucleotide.lower()
break
synthesized_strand += nucleotide
new_strands.append(synthesized_strand)
return(new_strands)
ddN(10,seq,'A',0.5)
['CTTGCGGCTATAGGa',
'CTTGCGGCTATa',
'CTTGCGGCTATa',
'CTTGCGGCTATAGGAATa',
'CTTGCGGCTa',
'CTTGCGGCTa',
'CTTGCGGCTa',
'CTTGCGGCTATa',
'CTTGCGGCTATAGGa',
'CTTGCGGCTATa']
To execute this function on all four types of ddNTPs with need to wrap it in a for loop iterating over the four possibilities:
for nt in 'ATCG':
ddN(10,seq,nt,0.5)
A bit about lists
To store the sequences being generated in the previous loop we will create and initialize a list called seq_run:
seq_run = []
for nt in 'ATCG':
seq_run.append(ddN(10,seq,nt,0.5))
you will see that the seq run is a two-dimensional list:
seq_run
[['CTTGCGGCTa',
'CTTGCGGCTATAGGa',
'CTTGCGGCTa',
'CTTGCGGCTATa',
'CTTGCGGCTATAGGa',
'CTTGCGGCTATa',
'CTTGCGGCTa',
'CTTGCGGCTATAGGAATAa',
'CTTGCGGCTa',
'CTTGCGGCTATa'],
['CTTGCGGCt', 'Ct', 'Ct', 'Ct', 'Ct', 'CTt', 'Ct', 'Ct', 'CTTGCGGCt', 'Ct'],
['CTTGc',
'c',
'c',
'c',
'c',
'CTTGCGGCTATAGGAATAAAAGGCTTTGc',
'c',
'CTTGCGGCTATAGGAATAAAAGGc',
'c',
'CTTGc'],
['CTTg',
'CTTGCg',
'CTTg',
'CTTg',
'CTTGCg',
'CTTGCGGCTATAGGAATAAAAg',
'CTTGCGGCTATAGGAATAAAAg',
'CTTg',
'CTTg',
'CTTg']]
as you will read in your next home assignment list elements can be addressed by “index”. The first element has the number 0:
seq_run[0]
['CTTGCGGCTa',
'CTTGCGGCTATAGGa',
'CTTGCGGCTa',
'CTTGCGGCTATa',
'CTTGCGGCTATAGGa',
'CTTGCGGCTATa',
'CTTGCGGCTa',
'CTTGCGGCTATAGGAATAa',
'CTTGCGGCTa',
'CTTGCGGCTATa']
A bit about dictionaries
Another way to store these data is in a dictionary, which is a collection of key:value pairs where a key and value can be anything:
seq_run = {}
for nt in 'ATCG':
seq_run[nt] = ddN(10,seq,nt,0.90)
seq_run
{'A': ['CTTGCGGCTATAGGAATAAAAGGCTTTGCGGGTAGTGACCGCGCCGCGTATGTAATTCATGGGTGTCGTCGCGCCCTCACa',
'CTTGCGGCTATAGGAATAAAAGGCTTTGCGGGTAGTGACCGCGCCGCGTATGTa',
'CTTGCGGCTATAGGAATAa',
'CTTGCGGCTATAGGAATAAAAGGCTTTGCGGGTa',
'CTTGCGGCTa',
'CTTGCGGCTATAGGAATAAAAGGCTTTGCGGGTAGTGACCGCGCCGCGTATGTAATTCATGGGTGTCGTCGCGCCCTCACAACTGCa',
'CTTGCGGCTATAGGa',
'CTTGCGGCTATAGGAATAAAa',
'CTTGCGGCTATAGGAATAAAAGGCTTTGCGGGTAGTGACCGCGCCGCGTATGTAATTCATGGGTGTCGTCGCGCCCTCACAACTGCAa',
'CTTGCGGCTATAGGAa'],
'T': ['CTTGCGGCTAt',
'CTTGCGGCTATAGGAATAAAAGGCTTt',
'CTTGCGGCTATAGGAATAAAAGGCTTTGCGGGTAGTGACCGCGCCGCGTATGTAATTCATGGGTGTCGTCGCGCCCTCACAACt',
'CTTGCGGCTATAGGAATAAAAGGCTTTGCGGGTAGTGACCGCGCCGCGTATGTAATTCATGGGTGTCGTCGCGCCCTCACAACTGCAAGGTCGTGGCACC',
'CTTGCGGCTATAGGAATAAAAGGCTTTGCGGGTAGTGACCGCGCCGCGTATGTAATt',
'CTTGCGGCTATAGGAATAAAAGGCTTTGCGGGTAGTGACCGCGCCGCGTAt',
'CTTGCGGCTATAGGAATAAAAGGCTTTGCGGGTAGTGACCGCGCCGCGTATGTAATTCAt',
'CTTGCGGCTATAGGAATAAAAGGCTTTGCGGGTAGTGACCGCGCCGCGTATGTAATTCATGGGTGTCGTCGCGCCCTCACAACTGCAAGGTCGTGGCACC',
'CTTGCGGCTATAGGAATAAAAGGCTTTGCGGGTAGTGACCGCGCCGCGTATGTAATTCAt',
'CTt'],
'C': ['CTTGCGGCTATAGGAATAAAAGGc',
'CTTGCGGCTATAGGAATAAAAGGc',
'CTTGCGGCTATAGGAATAAAAGGCTTTGCGGGTAGTGACCGCGCCGCGTATGTAATTCATGGGTGTc',
'CTTGCGGCTATAGGAATAAAAGGCTTTGCGGGTAGTGAc',
'c',
'CTTGCGGCTATAGGAATAAAAGGc',
'CTTGCGGCTATAGGAATAAAAGGCTTTGCGGGTAGTGACCGCGCCGCGTATGTAATTCATGGGTGTc',
'CTTGCGGc',
'CTTGCGGCTATAGGAATAAAAGGCTTTGCGGGTAGTGAc',
'CTTGCGGCTATAGGAATAAAAGGCTTTGCGGGTAGTGACCGCGCCGc'],
'G': ['CTTGCGGCTATAGg',
'CTTGCGGCTATAGGAATAAAAGGCTTTGCGGGTAGTGACCGCGCCGCGTATGTAATTCATGGGTg',
'CTTGCg',
'CTTGCGGCTATAGGAATAAAAGGCTTTGCGGGTAGTGACCGCGCCGCGTATGTAATTCATGGGTGTCGTCGCGCCCTCACAACTGCAAGGTCGTGGCACC',
'CTTg',
'CTTGCGGCTATAGGAATAAAAGg',
'CTTGCGGCTATAGGAATAAAAGGCTTTg',
'CTTGCGGCTATAGGAATAAAAGGCTTTGCGGGTAGTGACCGCg',
'CTTGCGGCTATAGGAATAAAAGGCTTTGCGg',
'CTTGCGGCTATAGGAATAAAAg']}
dictionary elements can be retrieved using a key:
seq_run['A']
['CTTGCGGCTATAGGAATAAAAGGCTTTGCGGGTAGTGACCGCGCCGCGTATGTAATTCATGGGTGTCGTCGCGCCCTCACa',
'CTTGCGGCTATAGGAATAAAAGGCTTTGCGGGTAGTGACCGCGCCGCGTATGTa',
'CTTGCGGCTATAGGAATAa',
'CTTGCGGCTATAGGAATAAAAGGCTTTGCGGGTa',
'CTTGCGGCTa',
'CTTGCGGCTATAGGAATAAAAGGCTTTGCGGGTAGTGACCGCGCCGCGTATGTAATTCATGGGTGTCGTCGCGCCCTCACAACTGCa',
'CTTGCGGCTATAGGa',
'CTTGCGGCTATAGGAATAAAa',
'CTTGCGGCTATAGGAATAAAAGGCTTTGCGGGTAGTGACCGCGCCGCGTATGTAATTCATGGGTGTCGTCGCGCCCTCACAACTGCAa',
'CTTGCGGCTATAGGAa']
Drawing a sequencing gel
Now that we can simulate and store newly synthesized sequencing strands terminated with ddNTPs let us try to draw a realistic representation of the sequencing gel. For this, we will use several components that will be discussed in much greater detail in the upcoming lectures. These components are:
pandas- a dataframe manipulation toolaltair- a statistical visualization library built on top ofvega-lightvisualization grammar
These two libraries will be used in almost all lectures concerning Python in this class.
Gel electophoresis separates molecules based on mass, shape, or charge. In the case of DNA all molecules are universally negatively charged and thus will always migrate
to (+) electrode. All our molecules are linear single-stranded pieces (our gel is denaturing) and so the only physical/chemical characteristic that distinguishes them is length.
Therefore the first thing we will do is to convert our sequences into their lengths. For this, we will initialize a new dictionary called seq_lengths:
seq_lengths = {'base':[],'length':[]}
for key in seq_run.keys():
for sequence in seq_run[key]:
seq_lengths['base'].append(key)
seq_lengths['length'].append(len(sequence))
seq_lengths
{'base': ['A',
'A',
'A',
'A',
'A',
'A',
'A',
'A',
'A',
'A',
'T',
'T',
'T',
'T',
'T',
'T',
'T',
'T',
'T',
'T',
'C',
'C',
'C',
'C',
'C',
'C',
'C',
'C',
'C',
'C',
'G',
'G',
'G',
'G',
'G',
'G',
'G',
'G',
'G',
'G'],
'length': [81,
54,
19,
34,
10,
87,
15,
21,
88,
16,
11,
27,
84,
100,
57,
51,
60,
100,
60,
3,
24,
24,
67,
39,
1,
24,
67,
8,
39,
47,
14,
65,
6,
100,
4,
23,
28,
43,
31,
22]}
now let’s import pandas:
import pandas as pd
and inject seq_lengths into a pandas dataframe:
sequences = pd.DataFrame(seq_lengths)
it looks pretty:
sequences
| base | length | |
|---|---|---|
| 0 | A | 81 |
| 1 | A | 54 |
| 2 | A | 19 |
| 3 | A | 34 |
| 4 | A | 10 |
| 5 | A | 87 |
| 6 | A | 15 |
| 7 | A | 21 |
| 8 | A | 88 |
| 9 | A | 16 |
| 10 | T | 11 |
| 11 | T | 27 |
| 12 | T | 84 |
| 13 | T | 100 |
| 14 | T | 57 |
| 15 | T | 51 |
| 16 | T | 60 |
| 17 | T | 100 |
| 18 | T | 60 |
| 19 | T | 3 |
| 20 | C | 24 |
| 21 | C | 24 |
| 22 | C | 67 |
| 23 | C | 39 |
| 24 | C | 1 |
| 25 | C | 24 |
| 26 | C | 67 |
| 27 | C | 8 |
| 28 | C | 39 |
| 29 | C | 47 |
| 30 | G | 14 |
| 31 | G | 65 |
| 32 | G | 6 |
| 33 | G | 100 |
| 34 | G | 4 |
| 35 | G | 23 |
| 36 | G | 28 |
| 37 | G | 43 |
| 38 | G | 31 |
| 39 | G | 22 |
In our data, there is a number of DNA fragments that have identical length (just look at the dataframe above). We can condense these by grouping dataframe entries first by nucleotide (['base']) and then by length (['length']). For each group we will then compute count and put it into a new column named, …, count:
sequences_grouped_by_length = sequences.groupby(
['base','length']
).agg(
count=pd.NamedAgg(
column='length',
aggfunc='count'
)
).reset_index()
sequences_grouped_by_length
| base | length | count | |
|---|---|---|---|
| 0 | A | 10 | 1 |
| 1 | A | 15 | 1 |
| 2 | A | 16 | 1 |
| 3 | A | 19 | 1 |
| 4 | A | 21 | 1 |
| 5 | A | 34 | 1 |
| 6 | A | 54 | 1 |
| 7 | A | 81 | 1 |
| 8 | A | 87 | 1 |
| 9 | A | 88 | 1 |
| 10 | C | 1 | 1 |
| 11 | C | 8 | 1 |
| 12 | C | 24 | 3 |
| 13 | C | 39 | 2 |
| 14 | C | 47 | 1 |
| 15 | C | 67 | 2 |
| 16 | G | 4 | 1 |
| 17 | G | 6 | 1 |
| 18 | G | 14 | 1 |
| 19 | G | 22 | 1 |
| 20 | G | 23 | 1 |
| 21 | G | 28 | 1 |
| 22 | G | 31 | 1 |
| 23 | G | 43 | 1 |
| 24 | G | 65 | 1 |
| 25 | G | 100 | 1 |
| 26 | T | 3 | 1 |
| 27 | T | 11 | 1 |
| 28 | T | 27 | 1 |
| 29 | T | 51 | 1 |
| 30 | T | 57 | 1 |
| 31 | T | 60 | 2 |
| 32 | T | 84 | 1 |
| 33 | T | 100 | 2 |
The following chart is created using the alt.Chart() function and passing the data as an argument. The mark_tick() function is used to create a tick chart with a thickness of 4 pixels.
The chart is encoded with two main axis:
- y-axis which represents the length of the data and is encoded by the
'length'field of the data. - x-axis which represents the base of the data and is encoded by the
'base'field of the data. The chart also encodes a color, it encodes the'count'field of the data, sets the legend toNone, and uses the'greys'scale from the Altair library.
Finally, the chart properties are set to a width of 100 pixels and a height of 800 pixels.
import altair as alt
alt.Chart(sequences_grouped_by_length).mark_tick(thickness=4).encode(
y = alt.Y('length:Q'),
x = alt.X('base'),
color=alt.Color('count:Q',legend=None,
scale=alt.Scale(scheme="greys"))
).properties(
width=100,
height=800)
And here is a color version of the same graph using just one line of the gel:
import altair as alt
alt.Chart(sequences_grouped_by_length).mark_tick(thickness=4).encode(
y = alt.Y('length:Q'),
color=alt.Color('base:N',#legend=None,
scale=alt.Scale(scheme="set1"))
).properties(
width=20,
height=800)
Putting everything together
# Generate random sequences
seq = ''
for _ in range(300):
seq += random.choice('ATCG')
seq
'GTCGATGCCTGTTTGACCTAACTGGCGTGAAGGCTATATCAGTTATCCCAAGCGTAGGCTTTCAATTCGCCCGGTTGCGTCGCCCGATTATCAATCGCGGAAGGTGGGTGCGATTGGAAGTCCAAAACCTTTATCCTGACACACTTTCTGACTCGGCTTGGCAATGGGAAGTGTAGAACGTAGCGGGGACCTACATCATATCGTACATAACTGAGACGTGCTCACCCGCAGAGATAAGAACTGCAATACCCGGGTGAATACTTGGGGAGTCTCACCCAGATGGTTGGCCTGATCCTCCCC'
# Function simulating a single run of a single polymerase molecule
def ddN(number_of_iterations, template, base, ddN_ratio):
new_strands = []
for _ in range(number_of_iterations):
synthesized_strand = ''
for nucleotide in template:
if nucleotide == base and random.random() > ddN_ratio:
synthesized_strand += nucleotide.lower()
break
synthesized_strand += nucleotide
new_strands.append(synthesized_strand)
return(new_strands)
# Generating simulated sequencing run
seq_run = {}
for nt in 'ATCG':
seq_run[nt] = ddN(100000,seq,nt,0.95)
# Computing lengths
seq_lengths = {'base':[],'length':[]}
for key in seq_run.keys():
for sequence in seq_run[key]:
seq_lengths['base'].append(key)
seq_lengths['length'].append(len(sequence))
# Converting dictionary into Pandas dataframe
sequences = pd.DataFrame(seq_lengths)
# Grouping by nucleotide and length
sequences_grouped_by_length = sequences.groupby(
['base','length']
).agg(
count=pd.NamedAgg(
column='length',
aggfunc='count'
)
).reset_index()
# Plotting (note the quadratic scale for realism)
import altair as alt
alt.Chart(sequences_grouped_by_length).mark_tick(thickness=4).encode(
y = alt.Y('length:Q',scale=alt.Scale(type='sqrt')),
x = alt.X('base'),
color=alt.Color('count:Q',legend=None,
scale=alt.Scale(type='log',scheme="greys")),
tooltip='count:Q'
).properties(
width=100,
height=800)
# Plotting using color
import altair as alt
alt.Chart(sequences_grouped_by_length).mark_tick(thickness=4).encode(
y = alt.Y('length:Q',scale=alt.Scale(type="sqrt")),
color=alt.Color('base:N',#legend=None,
scale=alt.Scale(scheme="set1")),
opacity=alt.Opacity('count:N',legend=None),
tooltip='count:Q'
).properties(
width=20,
height=800)
You've Finished the Tutorial
Key points
Sanger sequencing is sequencing by synthesis
Python is powerful
Frequently Asked Questions
Have questions about this tutorial? Have a look at the available FAQ pages and support channelsFeedback
Did you use this material as an instructor? Feel free to give us feedback on how it went.
Did you use this material as a learner or student? Click the form below to leave feedback.

Citing this Tutorial
- Anton Nekrutenko, Introduction to sequencing with Python (part one) (Galaxy Training Materials). https://training.galaxyproject.org/training-material/topics/data-science/tutorials/gnmx-lecture2/tutorial.html Online; accessed TODAY
- Hiltemann, Saskia, Rasche, Helena et al., 2023 Galaxy Training: A Powerful Framework for Teaching! PLOS Computational Biology 10.1371/journal.pcbi.1010752
- Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
Congratulations on successfully completing this tutorial!@misc{data-science-gnmx-lecture2, author = "Anton Nekrutenko", title = "Introduction to sequencing with Python (part one) (Galaxy Training Materials)", year = "", month = "", day = "", url = "\url{https://training.galaxyproject.org/training-material/topics/data-science/tutorials/gnmx-lecture2/tutorial.html}", note = "[Online; accessed TODAY]" } @article{Hiltemann_2023, doi = {10.1371/journal.pcbi.1010752}, url = {https://doi.org/10.1371%2Fjournal.pcbi.1010752}, year = 2023, month = {jan}, publisher = {Public Library of Science ({PLoS})}, volume = {19}, number = {1}, pages = {e1010752}, author = {Saskia Hiltemann and Helena Rasche and Simon Gladman and Hans-Rudolf Hotz and Delphine Larivi{\`{e}}re and Daniel Blankenberg and Pratik D. Jagtap and Thomas Wollmann and Anthony Bretaudeau and Nadia Gou{\'{e}} and Timothy J. Griffin and Coline Royaux and Yvan Le Bras and Subina Mehta and Anna Syme and Frederik Coppens and Bert Droesbeke and Nicola Soranzo and Wendi Bacon and Fotis Psomopoulos and Crist{\'{o}}bal Gallardo-Alba and John Davis and Melanie Christine Föll and Matthias Fahrner and Maria A. Doyle and Beatriz Serrano-Solano and Anne Claire Fouilloux and Peter van Heusden and Wolfgang Maier and Dave Clements and Florian Heyl and Björn Grüning and B{\'{e}}r{\'{e}}nice Batut and}, editor = {Francis Ouellette}, title = {Galaxy Training: A powerful framework for teaching!}, journal = {PLoS Comput Biol} }